Full API Documentation¶
Cost Function¶
Various estimators.
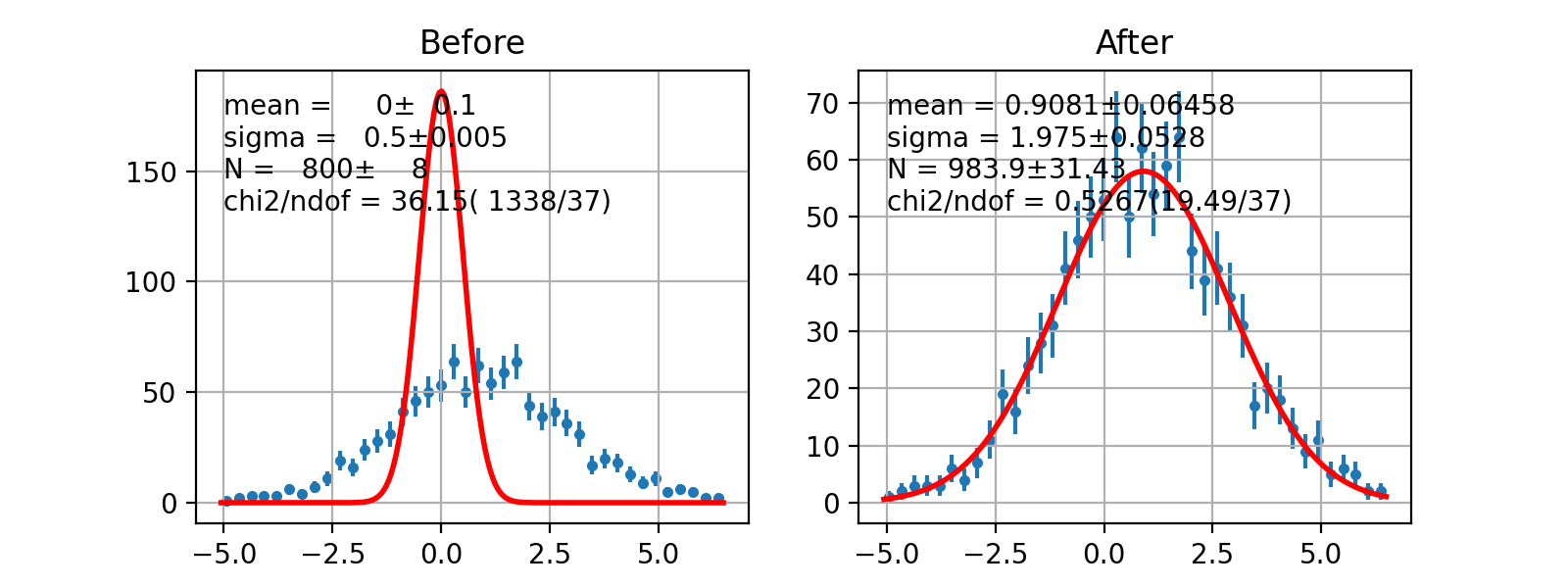
Unbinned Likelihood¶
- class probfit.costfunc.UnbinnedLH(f, data, weights=None, extended=False, extended_bound=None, extended_nint=100, badvalue=- 100000)¶
Construct -log(unbinned likelihood) from callable f and data points data. Currently can only do 1D fit.
\[\textrm{UnbinnedLH} = \sum_{x \in \textrm{data}} - \log f(x, arg, \ldots)\]Arguments
f callable object. PDF that describe the data. The parameters are parsed using iminuit’s
describe. The first positional arguement is assumed to be independent parameter. For example:def gauss(x, mu, sigma):#good pass def bad_gauss(mu, sigma, x):#bad pass
data 1D array of data.
weights Optional 1D array of weights. Default None(all 1).
badvalue Optional number. The value that will be used to represent log(lh) (notice no minus sign). When the likelihood is <= 0. This usually indicate your PDF is faraway from minimum or your PDF parameter has gone into unphysical region and return negative probability density. This should be a large negative number so that iminuit will avoid those points. Default -100000.
extended Set to True for extended fit. Default False. If Set to True the following term is added to resulting negative log likelihood
\[\textrm{ext term} = \int_{x \in \textrm{extended bound}}f(x, \textrm{args}, \ldots) \textrm{d} x\]extended_bound Bound for calculating extended term. Default None(minimum and maximum of data will be used).
extended_nint number pieces to sum up as integral for extended term (using simpson3/8). Default 100.
Note
There is a notable lack of sum_w2 for unbinned likelihood. I feel like the solutions are quite sketchy. There are multiple ways to implement it but they don’t really scale correctly. If you feel like there is a correct way to implement it feel free to do so and write document telling people about the caveat.
- __call__()¶
Compute sum of -log(lh) given positional arguments. Position argument will be passed to pdf with independent vairable from data is given as the frist argument.
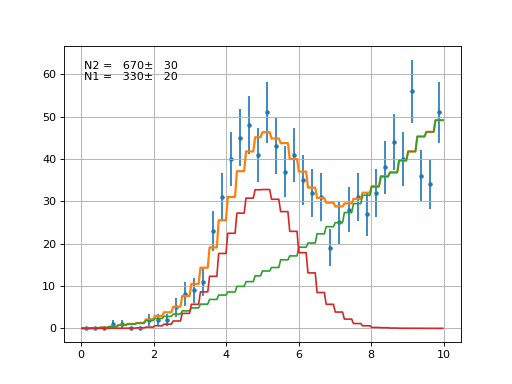
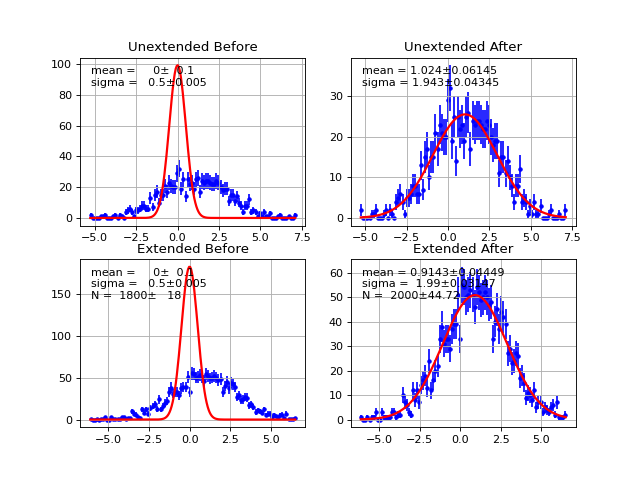
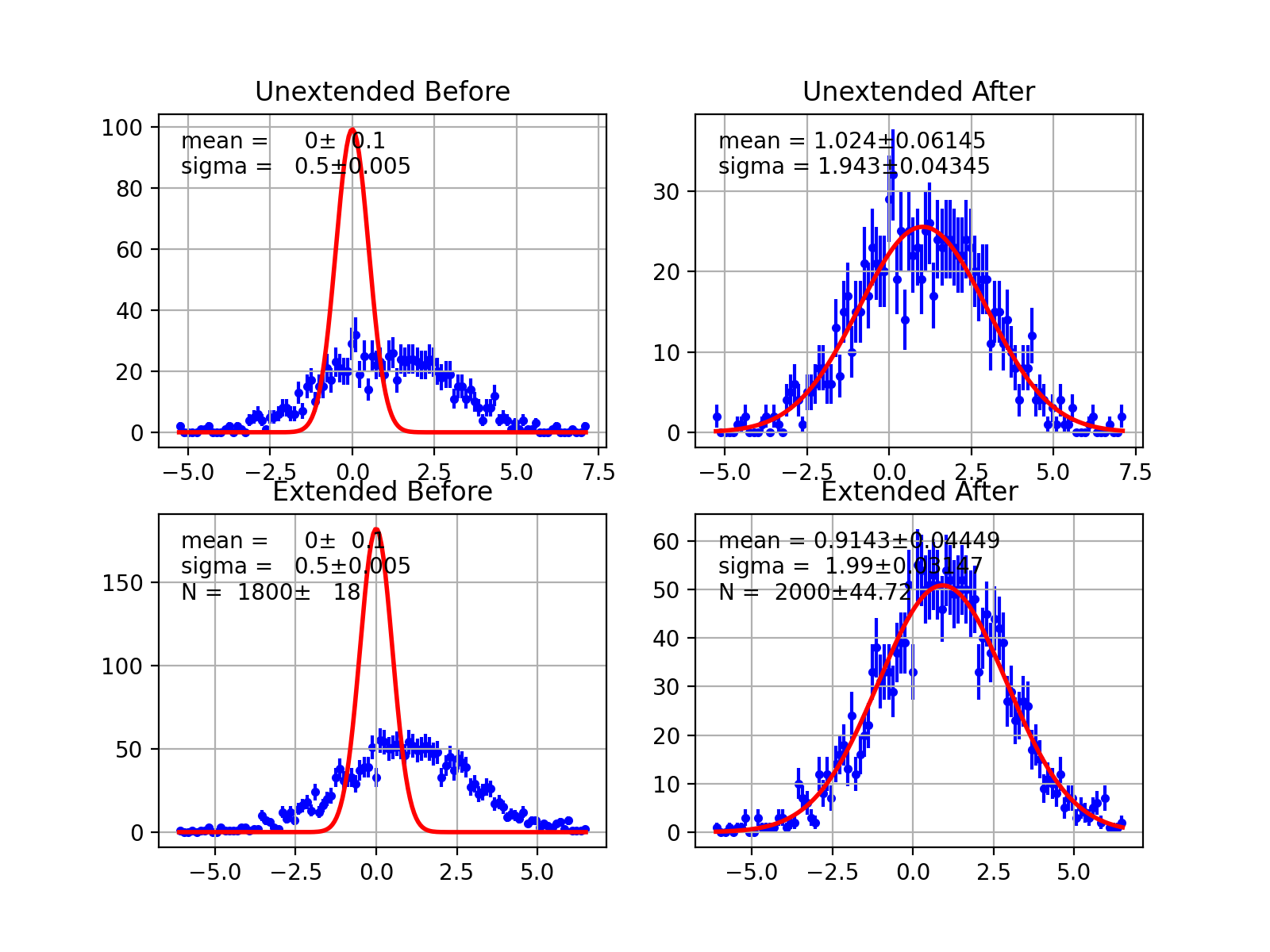
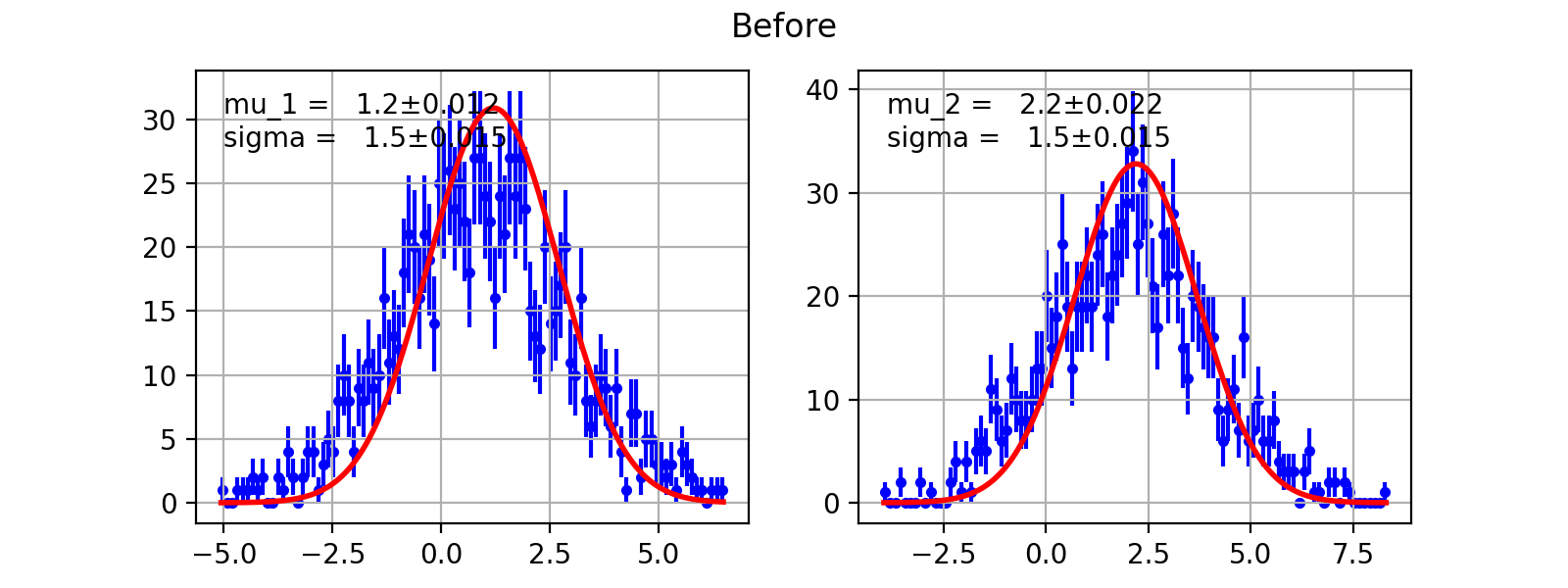
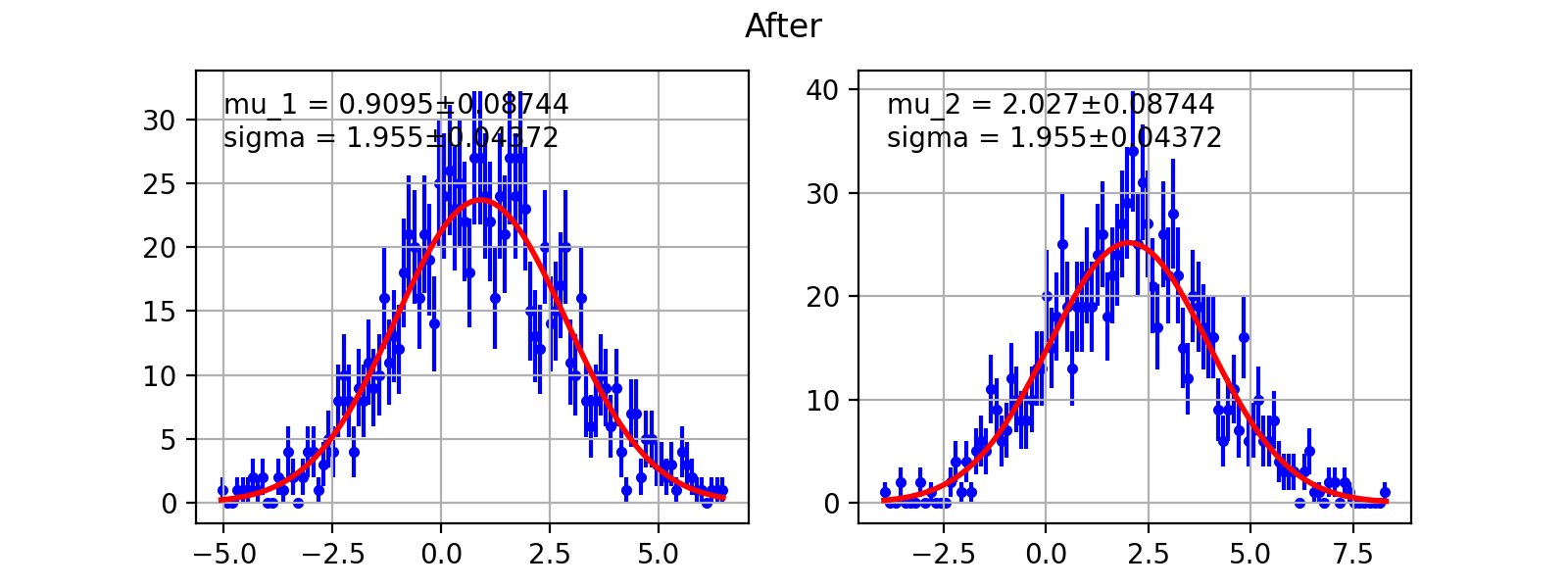
- draw(self, minuit=None, bins=100, ax=None, bound=None, parmloc=(0.05, 0.95), nfbins=200, print_par=True, args=None, errors=None, parts=False, show_errbars='normal', no_plot=False)¶
Draw comparison between histogram of data and pdf.
Arguments
minuit Optional but recommended
iminuit.Minuitobject. If minuit is notNone, the pdf will be drawn using minimum value from minuit and parameters and error will be shown. If minuit isNone, then pdf will be drawn using argument from the last call to__call__. DefaultNonebins number of bins for histogram. Default 100.
ax matplotlib axes. If not given it will be drawn on current axes
gca().bound bound for histogram. If
Noneis given the bound will be automatically determined from the data. If you given PDF that’s normalied to a region but some data is not within the bound the picture may look funny.parmloc location of parameter print out. This is passed directy to legend loc named parameter. Default (0.05,0.95).
nfbins how many point pdf should be evaluated. Default 200.
print_par print parameters and error on the plot. Default True.
args Optional. If minuit is not given, parameter value is determined from args. This can be dictionary of the form {‘a’:1.0, ‘b’:1.0} or list of values. Default None.
errors Optional dictionary of errors. If minuit is not given, parameter errors are determined from errors. Default None.
show_errbars Show error bars. Default ‘normal’
‘normal’ : error = sqrt( sum of weight )
‘sumw2’ : error = sqrt( sum of weight**2 )
None : no errorbars (shown as a step histogram)
no_plot Set this to True if you only want the return value
Returns
((data_edges, datay), (errorp,errorm), (total_pdf_x, total_pdf_y), parts)
- draw_residual(self, minuit=None, bins=100, ax=None, bound=None, parmloc=(0.05, 0.95), print_par=False, args=None, errors=None, errbar_algo='normal', norm=False, **kwargs)¶
Draw difference between data and PDF
Arguments
minuit Optional but recommended
iminuit.Minuitobject. If minuit is notNone, the pdf will be drawn using minimum value from minuit and parameters and error will be shown. If minuit isNone, then pdf will be drawn using argument from the last call to__call__. DefaultNonebins number of bins for histogram. Default 100.
ax matplotlib axes. If not given it will be drawn on current axes
gca().bound bound for histogram. If
Noneis given the bound will be automatically determined from the data. If you given PDF that’s normalied to a region but some data is not within the bound the picture may look funny.parmloc location of parameter print out. This is passed directy to legend loc named parameter. Default (0.05,0.95).
print_par print parameters and error on the plot. Default True.
args Optional. If minuit is not given, parameter value is determined from args. This can be dictionary of the form {‘a’:1.0, ‘b’:1.0} or list of values. Default None.
errors Optional dictionary of errors. If minuit is not given, parameter errors are determined from errors. Default None.
show_errbars Show error bars. Default True
errbar_algo How the error bars are calculated ‘normal’ : error = sqrt( sum of weight ) [Default] ‘sumw2’ : error = sqrt( sum of weight**2 )
norm Normalzed by the error bar or not. Default False.
kwargs Passed to
probfit.plotting.draw_residual()
Example
(Source code, png, hires.png, pdf)
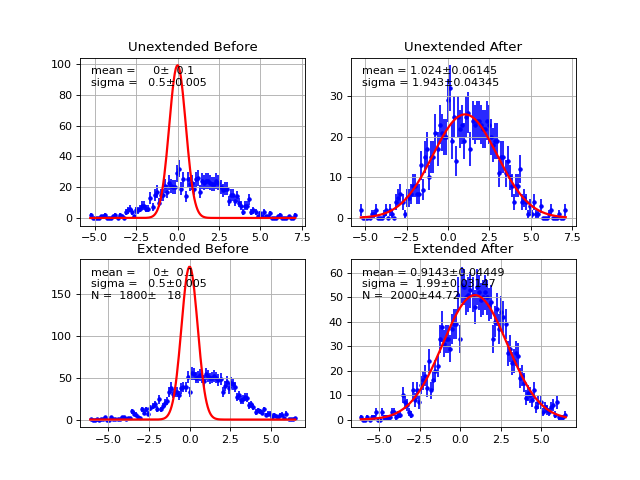
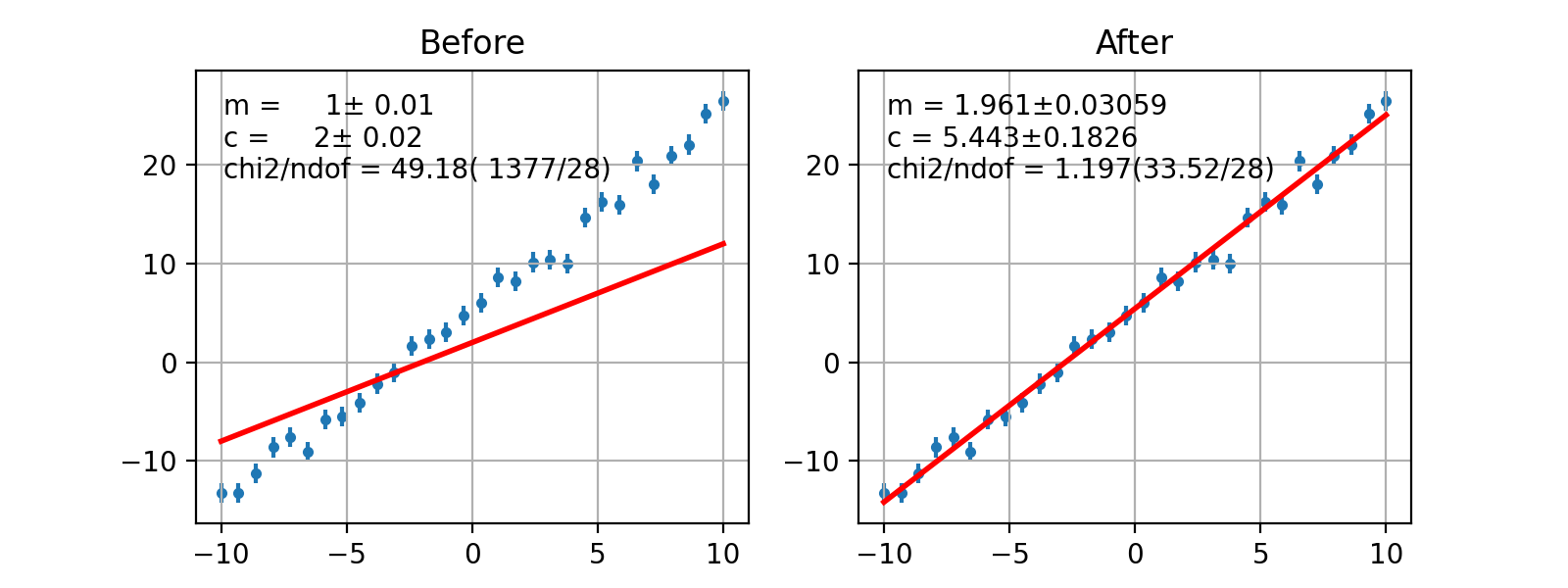
Binned Likelihood¶
- class probfit.costfunc.BinnedLH(f, data, bins=40, weights=None, weighterrors=None, bound=None, badvalue=1000000, extended=False, use_w2=False, nint_subdiv=1)¶
Create a Poisson Binned Likelihood object from given PDF f and data (raw points not histogram). Constant term and expected minimum are subtracted off (aka. log likelihood ratio). The exact calculation will depend on extended and use_w2 keyword parameters.
\[\textrm{BinnedLH} = -\sum_{i \in bins} s_i \times \left( h_i \times \log (\frac{E_i}{h_i}) + (h_i-E_i) \right)\]where
\(h_i\) is sum of weight of data in ith bin.
\(b_i\) is the width of ith bin.
\(N\) is total number of data. \(N = \sum_i h_i\).
\(E_i\) is expected number of occupancy in ith bin from PDF calculated using average of pdf value at both sides of the bin \(l_i, r_i\). The definition for \(E_i\) depends whether extended likelihood is requested.
If extended likelihood is requested (
extended=True):\[E_i = \frac{f(l_i, arg\ldots )+f(r_i, arg \ldots )}{2} \times b_i\]If extended likelihood is NOT requested (
extended=False):\[E_i = \frac{f(l_i, arg \ldots )+f(r_i, arg \ldots )}{2} \times b_i \times N\]Note
You are welcome to patch this with a the using real area. So that, it’s less sensitive to bin size. Last time I check ROOFIT used f evaluated at midpoint.
\(s_i\) is a scaled factor. It’s 1 if
sum_w2=False. It’s \(s_i = \frac{h_i}{\sum_{j \in \textrm{bin }i} w_j^2}\) ifsum_w2=True. The factor will scale the statistics to the unweighted data.
Note
You may wonder why there is \(h_i-E_i\) added at the end for each term of the sum. They sum up to zero anyway. The reason is the precision near the minimum. If we taylor expand the logarithmic term near \(h_i\approx E_i\) then the first order term will be \(h_i-E_i\). Subtracting this term at the end gets us the nice pure parabolic behavior for each term at the minimum.
Arguments
f callable object. PDF that describe the data. The parameters are parsed using iminuit’s
describe. The first positional arguement is assumed to be independent parameter. For example:def gauss(x, mu, sigma):#good pass def bad_gauss(mu, sigma, x):#bad pass
data 1D array of data if raw data; otherwise, this can be a tuple of contents, edges (like NumPy).
bins number of bins data should be histogrammed. Default 40.
weights Optional 1D array of weights. Default
None(all 1’s).weighterrors Optional 1D array of weight errors. Default
NoneThis is usually used for binned datasets where you want to manipulate each bin’s error. It doesn’t make sense if the data is unbinned data.bound tuple(min,max). Histogram bound. If
Noneis given, bound is automatically determined from data. Default None.badvalue Optional number. The value that will be used to represent log(lh) (notice no minus sign). When the likelihood is <= 0. This usually indicate your PDF is faraway from minimum or your PDF parameter has gone into unphysical region and return negative probability density. This should be a large POSITIVE number so that iminuit will avoid those points. Default 100000.
extended Boolean whether this likelihood should be extended likelihood or not. Default False.
use_w2 Scale -log likelihood so that to the original unweighted statistics. Default False.
nint_subdiv controls how BinnedLH do the integral to find expect number of event in each bin. The number represent the number of subdivisions in each bin to do simpson3/8 rule. Default 1.
- __call__()¶
Calculate sum -log(poisson binned likelihood) given positional arguments
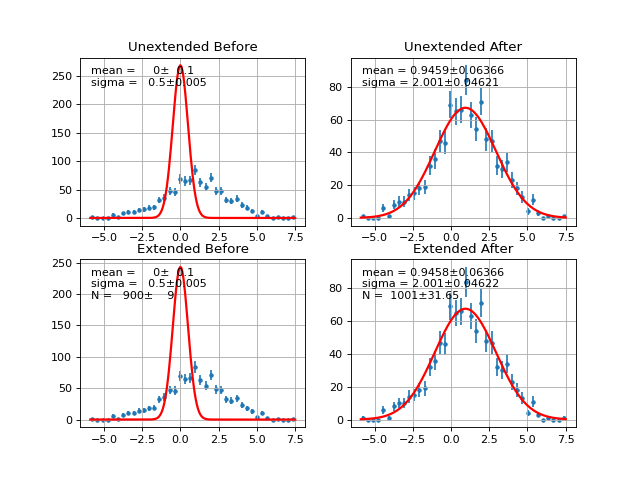
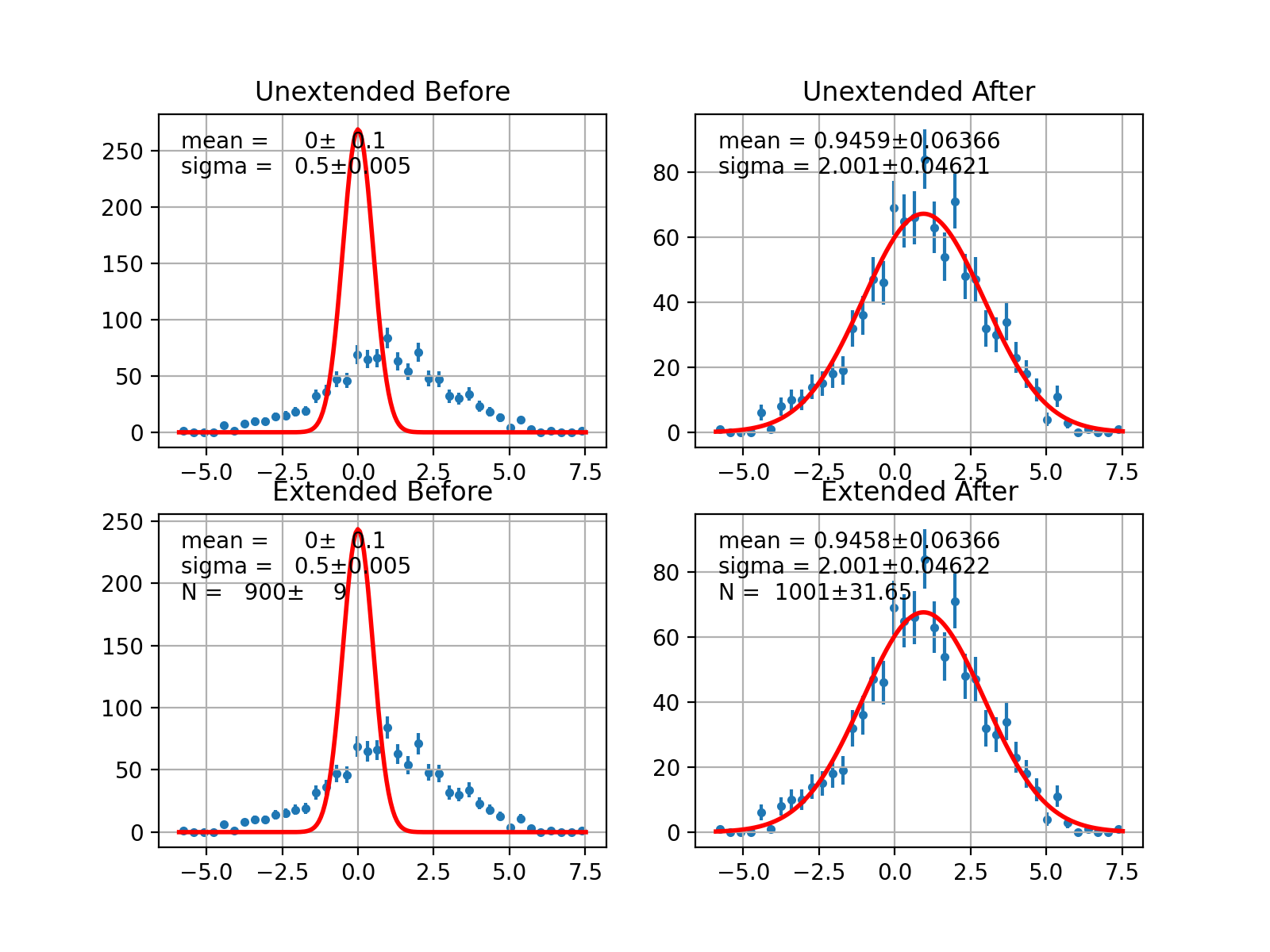
- draw(self, minuit=None, ax=None, parmloc=(0.05, 0.95), nfbins=200, print_par=True, args=None, errors=None, parts=False, no_plot=False)¶
Draw comparison between histogram of data and pdf.
Arguments
minuit Optional but recommended
iminuit.Minuitobject. If minuit is notNone, the pdf will be drawn using minimum value from minuit and parameters and error will be shown. If minuit isNone, then pdf will be drawn using argument from the last call to__call__. DefaultNoneax matplotlib axes. If not given it will be drawn on current axes
gca().parmloc location of parameter print out. This is passed directy to legend loc named parameter. Default (0.05,0.95).
nfbins how many point pdf should be evaluated. Default 200.
print_par print parameters and error on the plot. Default True.
no_plot Set this to True if you only want the return value
Returns
((data_edges, data_y), (errorp,errorm), (total_pdf_x, total_pdf_y), parts)
- draw_residual(self, minuit=None, ax=None, parmloc=(0.05, 0.95), print_par=False, args=None, errors=None, norm=False, **kwargs)¶
Draw difference between data and pdf.
Arguments
minuit Optional but recommended
iminuit.Minuitobject. If minuit is notNone, the pdf will be drawn using minimum value from minuit and parameters and error will be shown. If minuit isNone, then pdf will be drawn using argument from the last call to__call__. DefaultNoneax matplotlib axes. If not given it will be drawn on current axes
gca().parmloc location of parameter print out. This is passed directy to legend loc named parameter. Default (0.05,0.95).
print_par print parameters and error on the plot. Default True.
norm If True, draw difference normalized by error Default False.
kwargs Passed to
probfit.plotting.draw_residual()
Example
(Source code, png, hires.png, pdf)
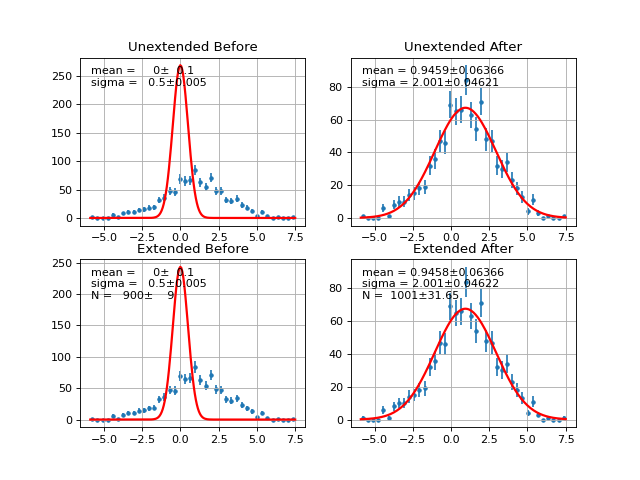
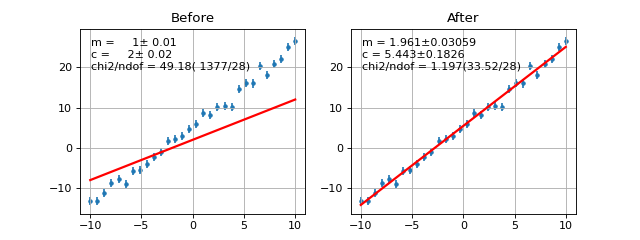
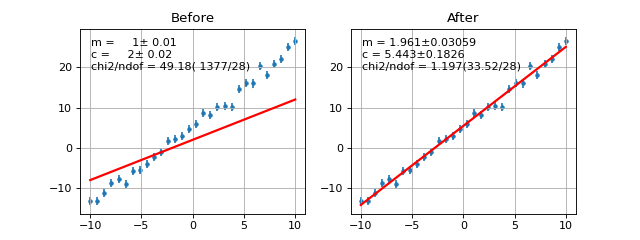
\(\chi^2\) Regression¶
- class probfit.costfunc.Chi2Regression(f, x, y, error=None, weights=None)¶
Create \(\chi^2\) regression object. This is for fitting funciton to data points(x,y) rather than fitting PDF to a distribution.
\[\textrm{Chi2Regression} = \sum_{i} w_i \times \left( \frac{f(x_i, arg \ldots) - y_i}{error_i} \right)^2\]Arguments
f callable object to describe line given by (x , y). The first positional arugment of f is assumed to be independent variable. Ex::
def gauss(x, mu, sigma):#good pass def bad_gauss(mu, sigma, x):#bad pass
x 1D array of independent variable
y 1D array of expected y
error optional 1D error array. If
Noneis given, it’s assumed to be all 1’s.weight 1D array weight for each data point.
- __call__()¶
Compute \(\chi^2\)
- draw(self, minuit=None, ax=None, parmloc=(0.05, 0.95), print_par=True, args=None, errors=None, parts=False, nbins=None, no_plot=False)¶
Draw comparison between points (x,**y**) and the function f.
Arguments
minuit Optional but recommended
iminuit.Minuitobject. If minuit is notNone, the pdf will be drawn using minimum value from minuit and parameters and error will be shown. If minuit isNone, then pdf will be drawn using argument from the last call to__call__. DefaultNoneax matplotlib axes. If not given it will be drawn on current axes
gca().parmloc location of parameter print out. This is passed directy to legend loc named parameter. Default (0.05,0.95).
print_par print parameters and error on the plot. Default True.
parts draw components of PDF. Default False.
no_plot Set this to true if you only want the return value
nbins draw the PDF curve using this number of bins, instead of (if None) using the data binning.
Returns
((data_x, data_y), (errorp,errorm), (total_pdf_x, total_pdf_y), parts)
- draw_residual(self, minuit=None, ax=None, args=None, errors=None, grid=True, norm=False)¶
Example
(Source code, png, hires.png, pdf)
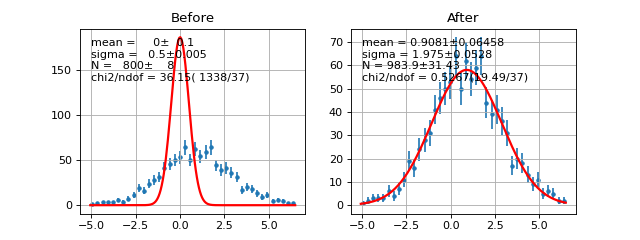
Binned \(\chi^2\)¶
- class probfit.costfunc.BinnedChi2(f, data, bins=40, weights=None, bound=None, sumw2=False, nint_subdiv=1, data_binned=False, bin_contents=None, bin_edges=None)¶
Create Binned Chi2 Object. It calculates chi^2 assuming poisson statistics.
\[\textrm{BinnedChi2} = \sum_{i \in \textrm{bins}} \left( \frac{h_i - f(x_i,arg \ldots) \times b_i \times N}{err_i} \right)^2\]Where \(err_i\) is
\(\sqrt{\sum_{j \in \textrm{bin}_i} w_j}\) if
sum_w2=False.\(\sqrt{\sum_{j \in \textrm{bin}_i} w_j^2}\) if
sum_w2=True.
Arguments
f callable object. PDF describing data. The first positional arugment of f is assumed to be independent variable. Ex::
def gauss(x, mu, sigma):#good pass def bad_gauss(mu, sigma, x):#bad pass
data 1D array of data if raw data; otherwise, this can be a tuple of contents, edges (like NumPy).
bins Optional number of bins to histogram data. Default 40.
weights 1D array weights.
bound tuple(min,max) bound of histogram. If
Noneis given it’s automatically determined from the data.sumw2 scale the error using \(\sqrt{\sum_{j \in \textrm{bin}_i} w_j^2}\).
nint_subdiv controls how BinnedChi2 do the integral to find expect number of event in each bin. The number represent the number of subdivisions in each bin to do simpson3/8. Default 1.
- __call__()¶
Calculate \(\chi^2\) given positional arguments
- draw(self, minuit=None, ax=None, parmloc=(0.05, 0.95), nfbins=200, print_par=True, args=None, errors=None, parts=False, no_plot=False)¶
Draw comparison histogram of data and the function f.
Arguments
minuit Optional but recommended
iminuit.Minuitobject. If minuit is notNone, the pdf will be drawn using minimum value from minuit and parameters and error will be shown. If minuit isNone, then pdf will be drawn using argument from the last call to__call__. DefaultNoneax matplotlib axes. If not given it will be drawn on current axes
gca().parmloc location of parameter print out. This is passed directy to legend loc named parameter. Default (0.05,0.95).
nfbins number of points to calculate f
print_par print parameters and error on the plot. Default True.
no_plot Set this to true if you only want the return value
Returns
((data_edges, data_y), (errorp,errorm), (total_pdf_x, total_pdf_y), parts)
Example
(Source code, png, hires.png, pdf)
Simultaneous Fit¶
- class probfit.costfunc.SimultaneousFit(factors=None, *arg, prefix=None, skip_prefix=None)¶
Construct simultaneous fit from given cost functions.
Arguments
factors Optional factor array. If not None, each cost function is scaled by factors[i] before being summed up. Default None.
prefix Optional list of prefix. Add prefix to variable name of each cost function so that you don’t accidentally merge them. Default None.
skip_prefix list of variable names that prefix should not be applied to. Useful if you want to prefix them and shared some of them.
- __call__(*args, **kwargs)¶
Call self as a function.
- args_and_error_for(self, findex, minuit=None, args=None, errors=None)¶
convert argument from minuit/dictionary/errors to argument and error for cost function with index findex
- draw(self, minuit=None, args=None, errors=None, **kwds)¶
Draw each pdf along with data on plotting grid
return list of return values from each cost function
Example
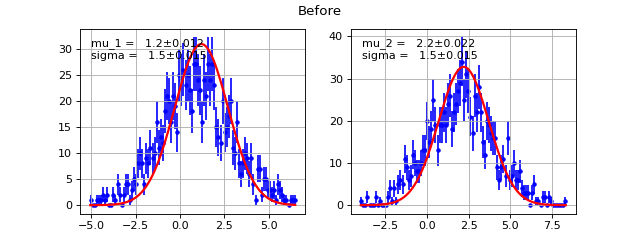
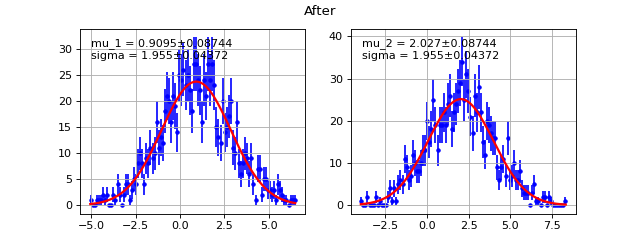
Functor¶
Manipulate and combined your pdf in various ways.
Extended¶
- class probfit.functor.Extended(f, extname='N')¶
Transformed given f into extended from.
def f(x,mu,sigma): return gaussian(x,mu,sigma) g = Extended(f) #g is equivalent to N*f(x,mu,sigma) describe(g) #('x','mu','sigma','N') #g is equivalent to def g_equiv(x, mu, sigma, N): return N*f(x, mu, sigma)
Arguments
f call object. PDF.
extname optional string. Name of the extended parameter. Default ‘N’
Normalized¶
- class probfit.functor.Normalized(f, bound, nint=300, warnfloat=1)¶
Transformed PDF in to a normalized version. The normalization factor is cached according the shape parameters(all arguments except the first one).
def f(x, a, b, c): return do_something(x, a, b, c) g = Normalized(f, (0., 1.)) #g is eqivalent to (shown here without cache) def g_equiv(x, a, b, c): return f(x, a, b, c)/Integrate(f(x, a, b, c), range=(0., 1.))
Arguments
f function to normalized.
bound bound of the normalization.
nint optional number of pieces to integrate. Default 300.
warnfloat optinal number of times it should warn if integral of the given function is really small. This usually indicate you bound doesn’t make sense with given parameters.
Note
Integration implemented here is just a simple trapezoid rule. You are welcome to implement something better and submit a pull request.
Warning
Never reused Normalized object with different parameters in the same pdf.
#DO NOT DO THIS def f(x,y,z): do_something(x,y,z) pdf1 = Normalized(f,(0,1)) #h has it's own cache pdf2 = rename(pdf1,['x','a','b'])#don't do this totalpdf = Add2PdfNorm(pdf1,pdf2)
The reason is that Normalized has excatly one cache value. Everytime it’s called with different parameters the cache is invalidate and it will recompute the integration which takes a long time. For the example given above, when calling totalpdf, calling to pdf2 will always invalidate pdf1 cache causing it to recompute integration for every datapoint x. The fix is easy:
#DO THIS INSTEAD def f(x,y,z): do_something(x,y,z) pdf1 = Normalized(f,(0,1)) #h has it's own cache pdf2_temp = Normalized(f,(0,1)) #own separate cache pdf2 = rename(pdf2_temp,['x','a','b']) totalpdf = Add2PdfNorm(pdf1,pdf2)
Convolve¶
- class probfit.functor.Convolve(f, g, gbound, nbins=1000)¶
Make convolution from supplied f and g. If your functions are analytically convolutable you will be better off implementing analytically. This functor is implemented using numerical integration with bound there are numerical issue that will, in most cases, lightly affect normalization.s
Argument from f and g is automatically merge by name. For example,
f = lambda x, a, b, c: a*x**2+b*x+c g = lambda x, a, sigma: gaussian(x,a,sigma) h = Convolve(f,g,gbound) describe(h)#['x','a','b','c','sigma'] #h is equivalent to def h_equiv(x, a, b, c, sigma): return Integrate(f(x-t, a, b, c)*g(x, a, b, c), t_range=gbound)
\[\text{Convolve(f,g)}(t, arg \ldots) = \int_{\tau \in \text{gbound}} f(t-\tau, arg \ldots)\times g(t, arg\ldots) \, \mathrm{d}\tau\]Argument
f Callable object, PDF.
g Resolution function.
gbound Bound of the resolution. Supplied something such that g(x,*arg) is near 0 at the edges. Current implementation is multiply reverse slide add straight up from the definition so this bound is important. Overbounding is recommended.
nbins Number of bins in multiply reverse slide add. Default(1000)
Note
You may be worried about normalization. By the property of convolution:
\[\int_{\mathbf{R}^d}(f*g)(x) \, dx=\left(\int_{\mathbf{R}^d}f(x) \, dx\right)\left(\int_{\mathbf{R}^d}g(x) \, dx\right).\]This means if you convolute two normalized distributions you get back a normalized distribution. However, since we are doing numerical integration here we will be off by a little bit.
BlindFunc¶
- class probfit.functor.BlindFunc(f, toblind, seedstring, width=1, signflip=True)¶
Transform given parameter(s) in the given f by a random shift so that the analyst won’t see the true fitted value.
\[BlindFunc(f, ['y','z'], '123')(x, y , z) = f(x, y\pm \delta, z)\]def f(x,mu,sigma): return gaussian(x,mu,sigma) g= BlindFunc(f, toblind=['mu','sigma'], seedstring= 'abcxyz', width=1, signflip=True) describe(g) # ['x', 'mu', 'sigma']
Arguments
f call object. A function or PDF.
toblind a list of names of parameters to be blinded. Can be a scalar if only one.
seedstring a string random number seed to control the random shift
width a Gaussian width that controls the random shift
signflip if True, sign of the parameter may be flipped before being shifted.
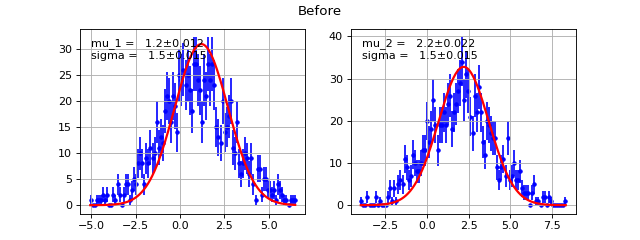
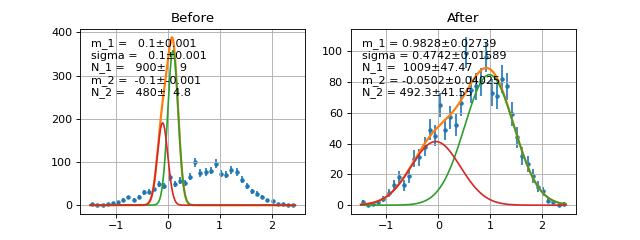
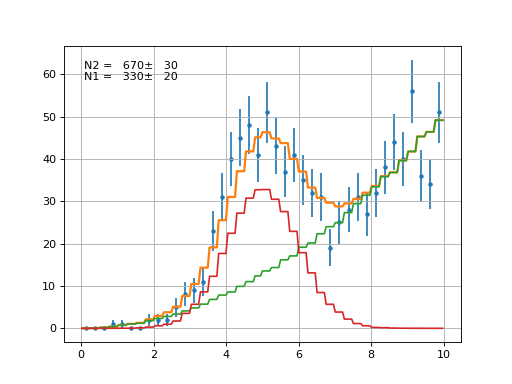
AddPdf¶
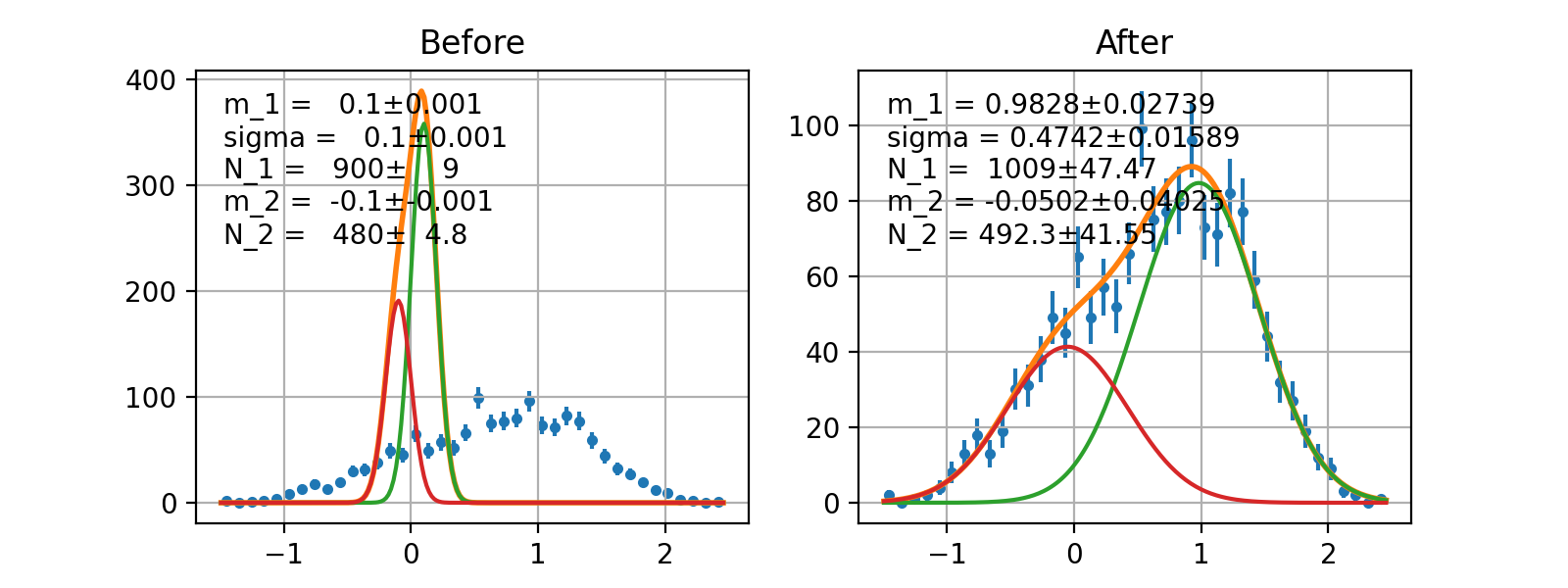
- class probfit.functor.AddPdf(prefix=None, *arg, factors=None, skip_prefix=None)¶
Directly add PDF without normalization nor factor. Parameters are merged by names.
def f(x, a, b, c): return do_something(x,a,b,c) def g(x, d, a, e): return do_something_else(x, d, a, e) h = AddPdf(f, g)# you can do AddPdf(f, g, h) #h is equivalent to def h_equiv(x, a, b, c, d, e): return f(x, a, b, c) + g(x, d, a, e)
Arguments
prefix array of prefix string with length equal to number of callable object passed. This allows you to add two PDF without having parameters from the two merge.
h2 = AddPdf(f, g, prefix=['f','g']) #h is equivalent to def h2_equiv(x, f_a, f_b, f_c, g_d, g_a, g_e): return f(x, f_a, f_b, f_c) + g(x, g_d, g_a, g_e)
factors list of callable factor function if given Add pdf will simulate the pdf of the form:
factor[0]*f + factor[1]*g
Note that all argument for callable factors will be prefixed (if given) as opposed to skipping the first one for pdf list. If None is given, all factors are assume to be constant 1. Default None.
skip_prefix list of variable that should not be prefixed. Default None. This is useful when you want to mix prefixing and sharing some of variable.
Example
(Source code, png, hires.png, pdf)
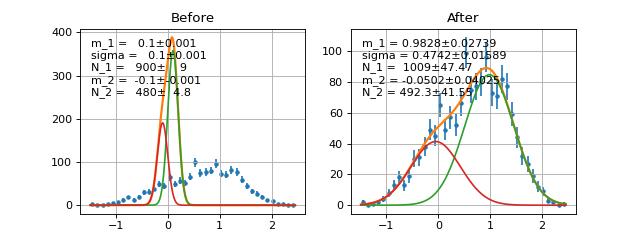
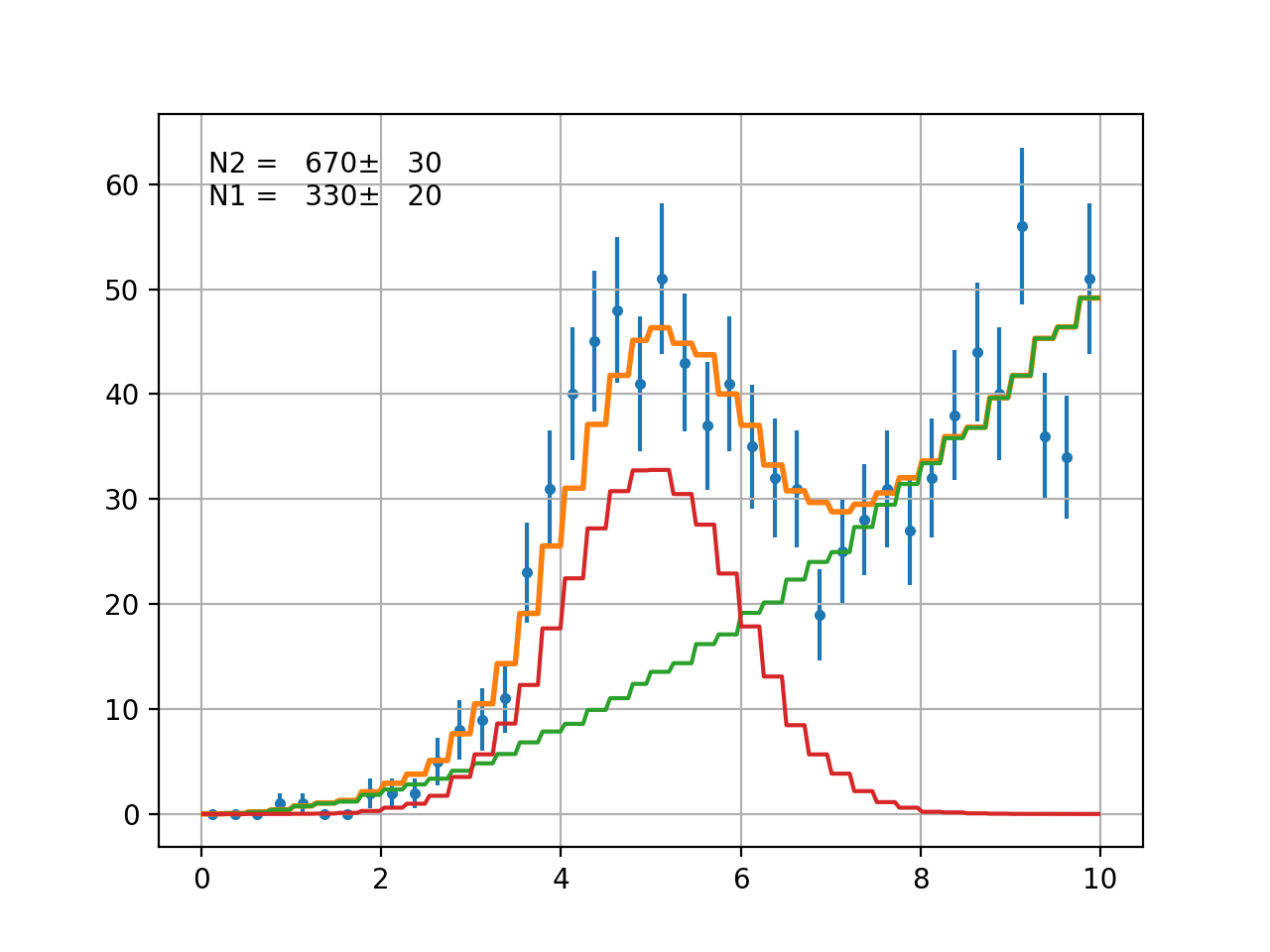
AddPdfNorm¶
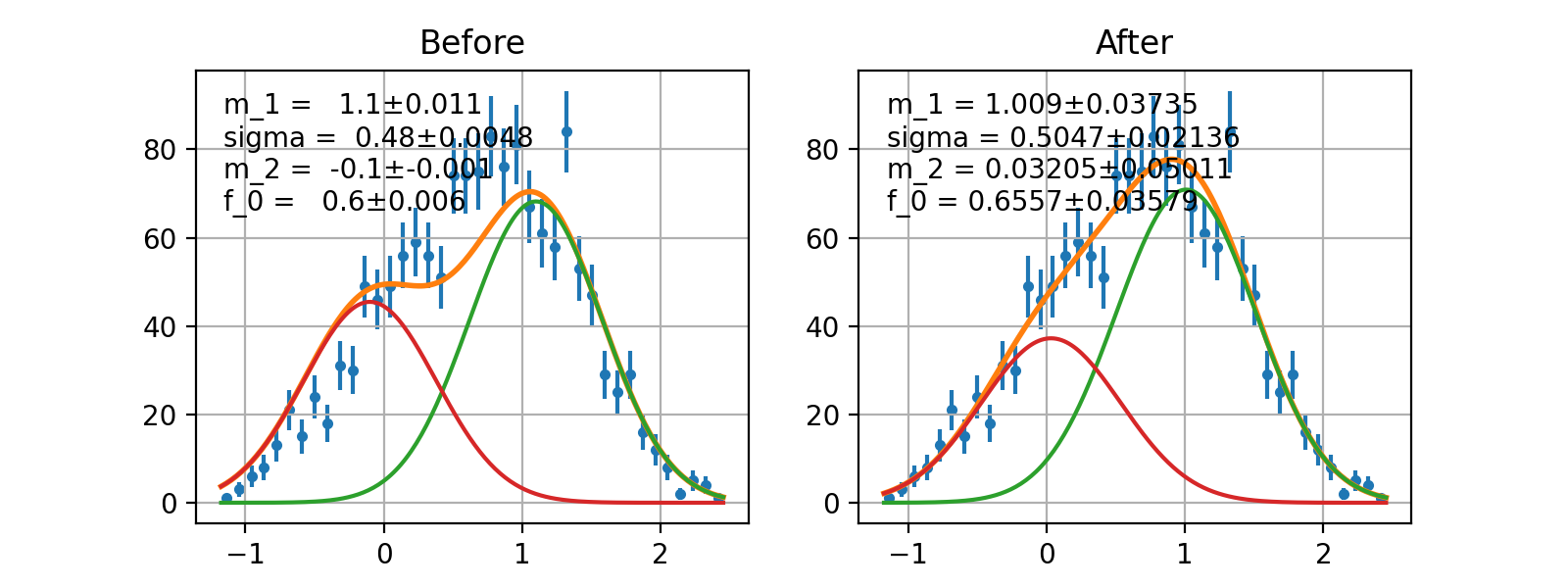
- class probfit.functor.AddPdfNorm(facname=None, *arg, prefix=None, skip_prefix=None)¶
Add PDF with normalization factor. Parameters are merged by name.
def f(x, a, b, c): return do_something(x, a, b, c) def g(x, d, a, e): return do_something_else(x, d, a, e) def p(x, b, a, c): return do_something_other_thing(x,b,a,c) h = Add2PdfNorm(f, g, p) #h is equivalent to def h_equiv(x, a, b, c, d, e, f_0, f_1): return f_0*f(x, a, b, c)+ \ f_1*g(x, d, a, e)+ (1-f_0-f_1)*p(x, b, a, c)
Arguments
facname optional list of factor name of length=. If None is given factor name is automatically chosen to be f_0, f_1 etc. Default None.
prefix optional prefix list to prefix arguments of each function. Default None.
skip_prefix optional list of variable that prefix will not be applied to. Default None(empty).
Example
(Source code, png, hires.png, pdf)
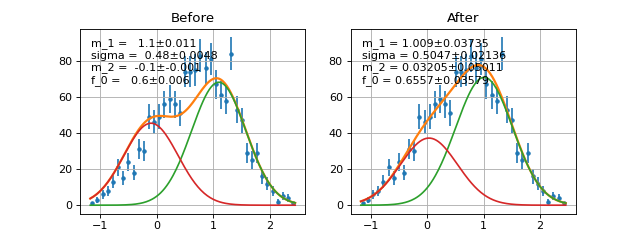
rename¶
- probfit.funcutil.rename(f, newarg)¶
Rename function parameters.
def f(x,y,z): return do_something(x,y,z) g = rename(f, ['x','a','b']) print describe(g) # ['x','a','b'] #g is equivalent to def g_equiv(x,a,b): return f(x,a,b)
Arguments
f callable object
newarg list of new argument names
Returns
function with new argument.
Decorator¶
- class probfit.decorator.normalized(bound, nint=1000)¶
Normalized decorator
Arguments
bound normalized bound
nint option number of integral pieces. Default 1000.
See also
- class probfit.decorator.extended(extname='N')¶
Extended decorator
Arguments
extname extended parameter name. Default ‘N’
See also
Builtin PDF¶
Builtin PDF written in cython.
gaussian¶
- probfit.pdf.gaussian(double x, double mean, double sigma) → double¶
Normalized gaussian.
\[f(x; mean, \sigma) = \frac{1}{\sqrt{2\pi}\sigma} \exp \left[ -\frac{1}{2} \left(\frac{x-mean}{\sigma}\right)^2 \right]\]
(Source code, png, hires.png, pdf)
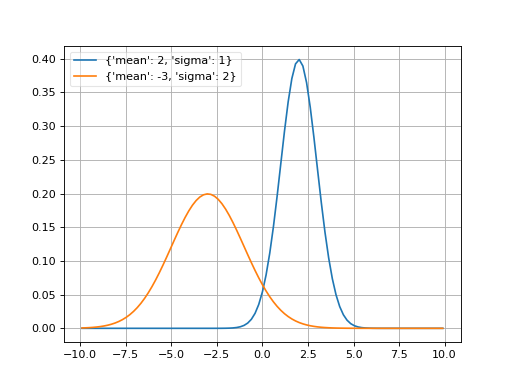
cauchy¶
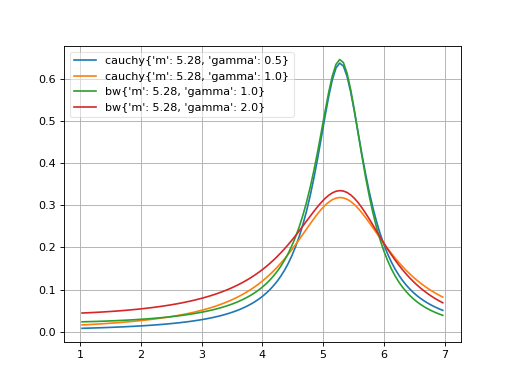
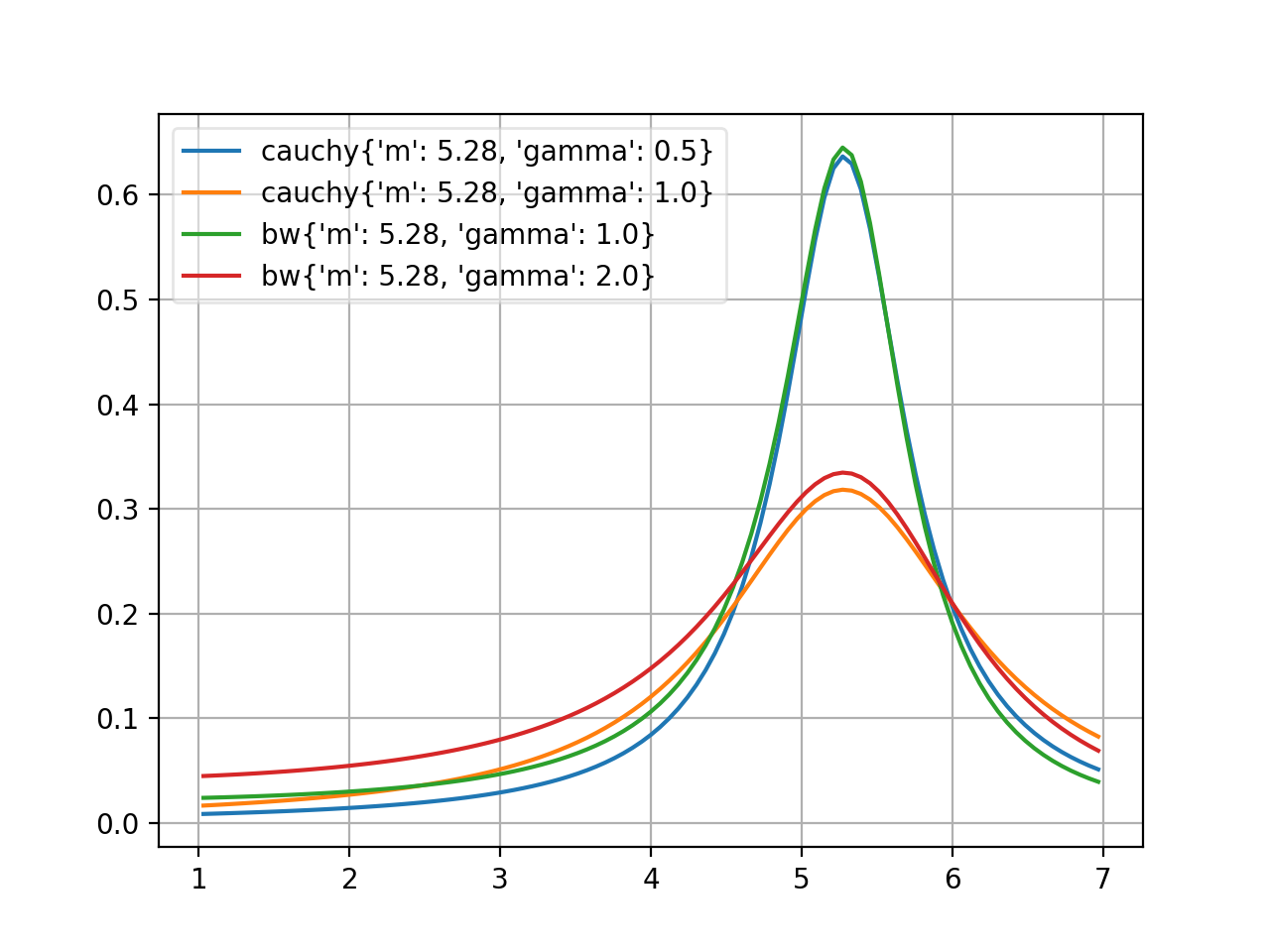
- probfit.pdf.cauchy(double x, double m, double gamma) → double¶
Cauchy distribution aka non-relativistic Breit-Wigner
\[f(x, m, \gamma) = \frac{1}{\pi \gamma \left[ 1+\left( \frac{x-m}{\gamma} \right)^2\right]}\]See also
breitwigner()(Source code, png, hires.png, pdf)
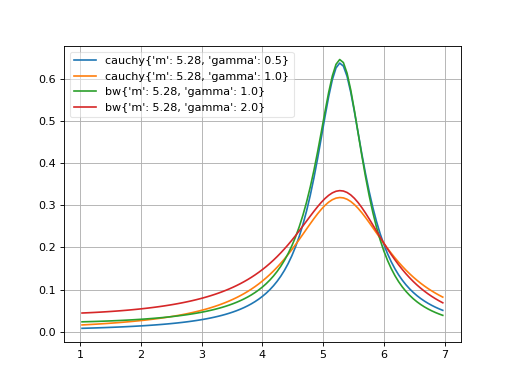
Breit-Wigner¶
- probfit.pdf.rtv_breitwigner(double x, double m, double gamma) → double¶
Normalized Relativistic Breit-Wigner
\[f(x; m, \Gamma) = N\times \frac{1}{(x^2-m^2)^2+m^2\Gamma^2}\]where
\[N = \frac{2 \sqrt{2} m \Gamma \gamma }{\pi \sqrt{m^2+\gamma}}\]and
\[\gamma=\sqrt{m^2\left(m^2+\Gamma^2\right)}\]See also
(Source code, png, hires.png, pdf)
crystalball¶
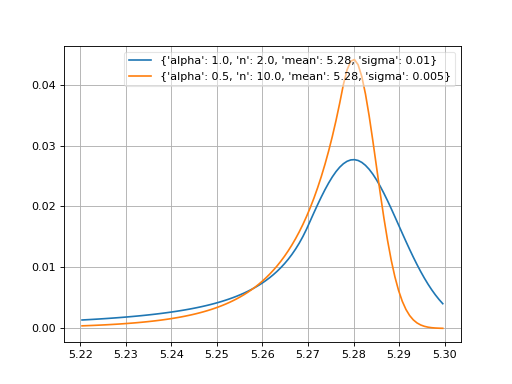
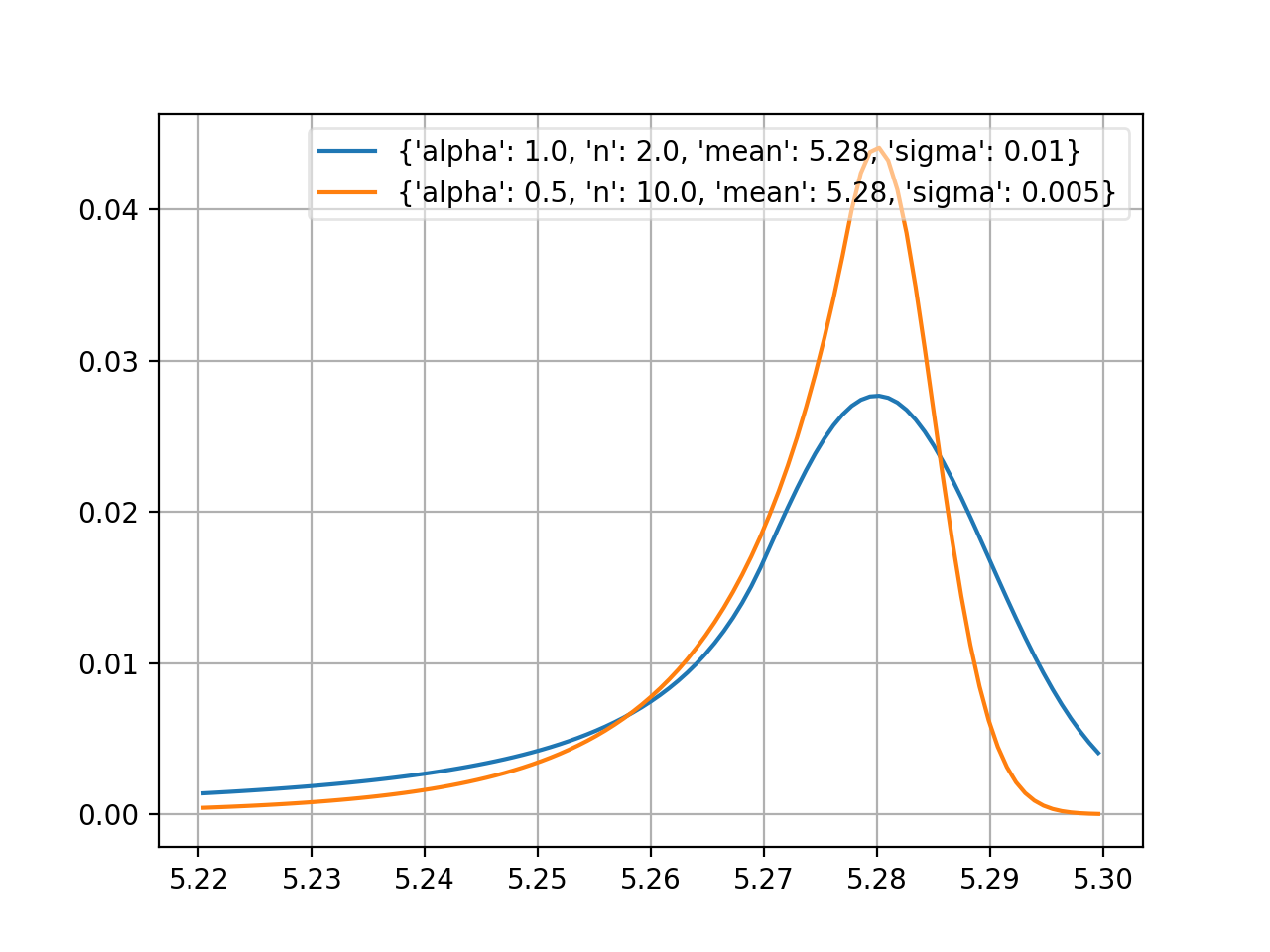
- probfit.pdf.crystalball(double x, double alpha, double n, double mean, double sigma) → double¶
Unnormalized crystal ball function. If alpha > 0, the non-Gaussian tail is on the left. Otherwise, the tail is on the right.
\[\begin{split}f(x;\alpha,n,mean,\sigma) = \begin{cases} \exp\left( -\frac{1}{2} \delta^2 \right) & \mbox{if } \delta>-\alpha \\ \left( \frac{n}{|\alpha|} \right)^n \left( \frac{n}{|\alpha|} - |\alpha| - \delta \right)^{-n} \exp\left( -\frac{1}{2}\alpha^2\right) & \mbox{if } \delta \leq \alpha \end{cases}\end{split}\]where
\(\delta = \frac{x-mean}{\sigma}\)
(Source code, png, hires.png, pdf)
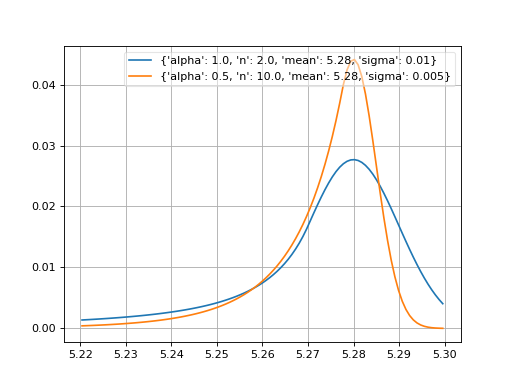
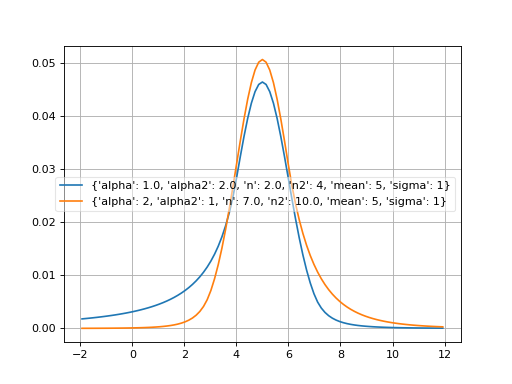
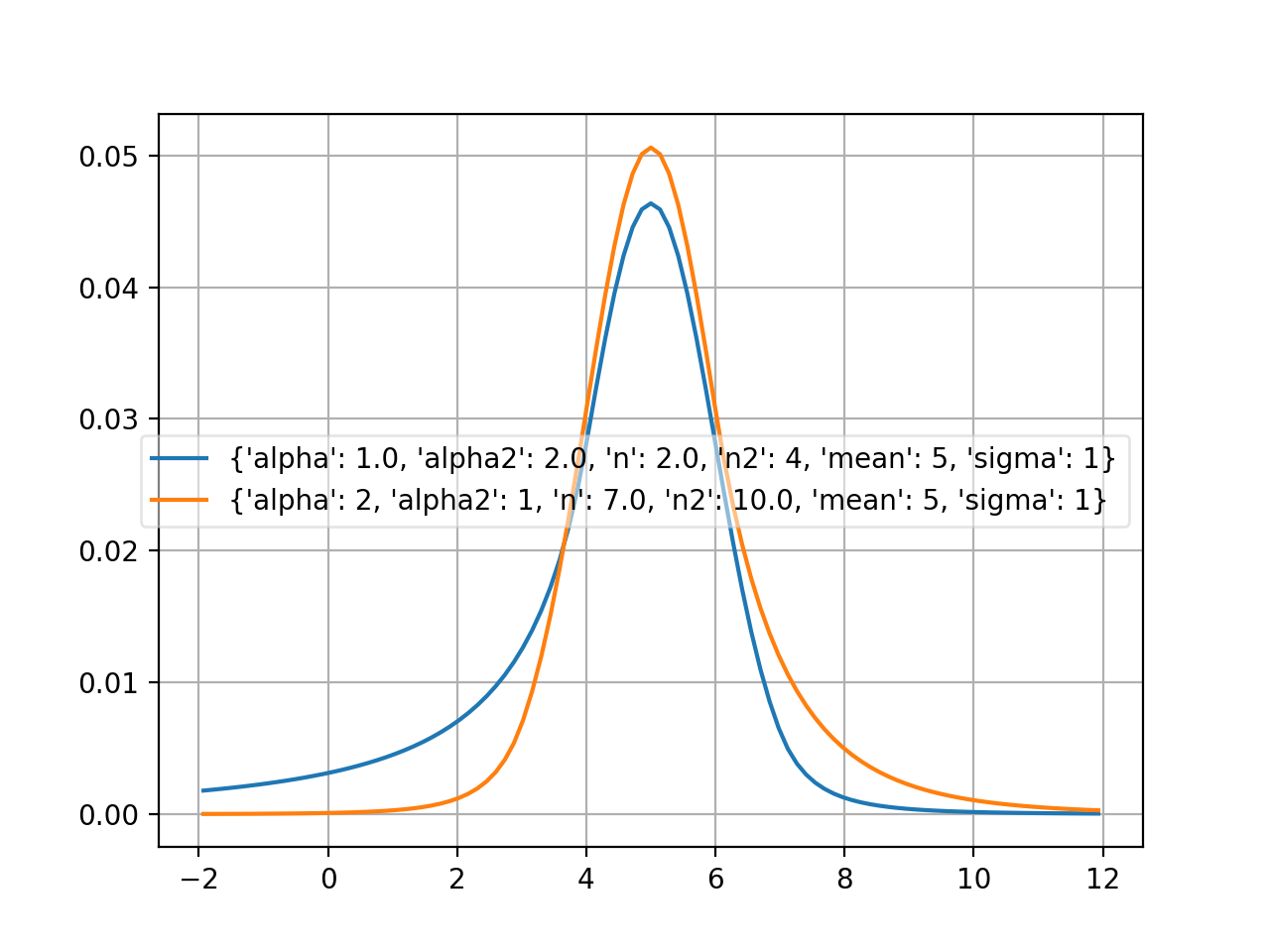
doublecrystalball¶
- probfit.pdf.doublecrystalball(double x, double alpha, double alpha2, double n, double n2, double mean, double sigma) → double¶
Unnormalized double crystal ball function A gaussian core with two power tails
(Source code, png, hires.png, pdf)
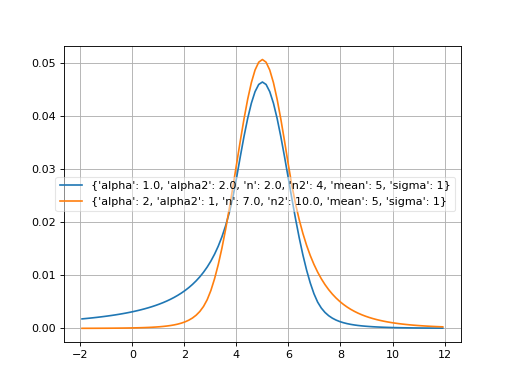
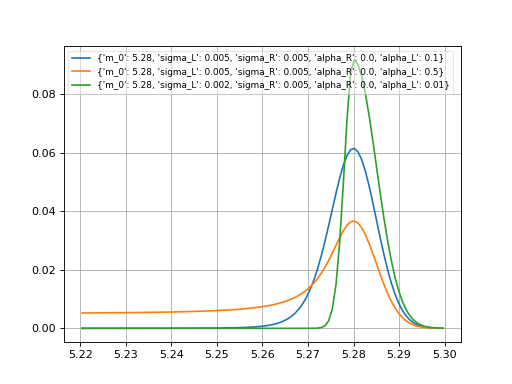
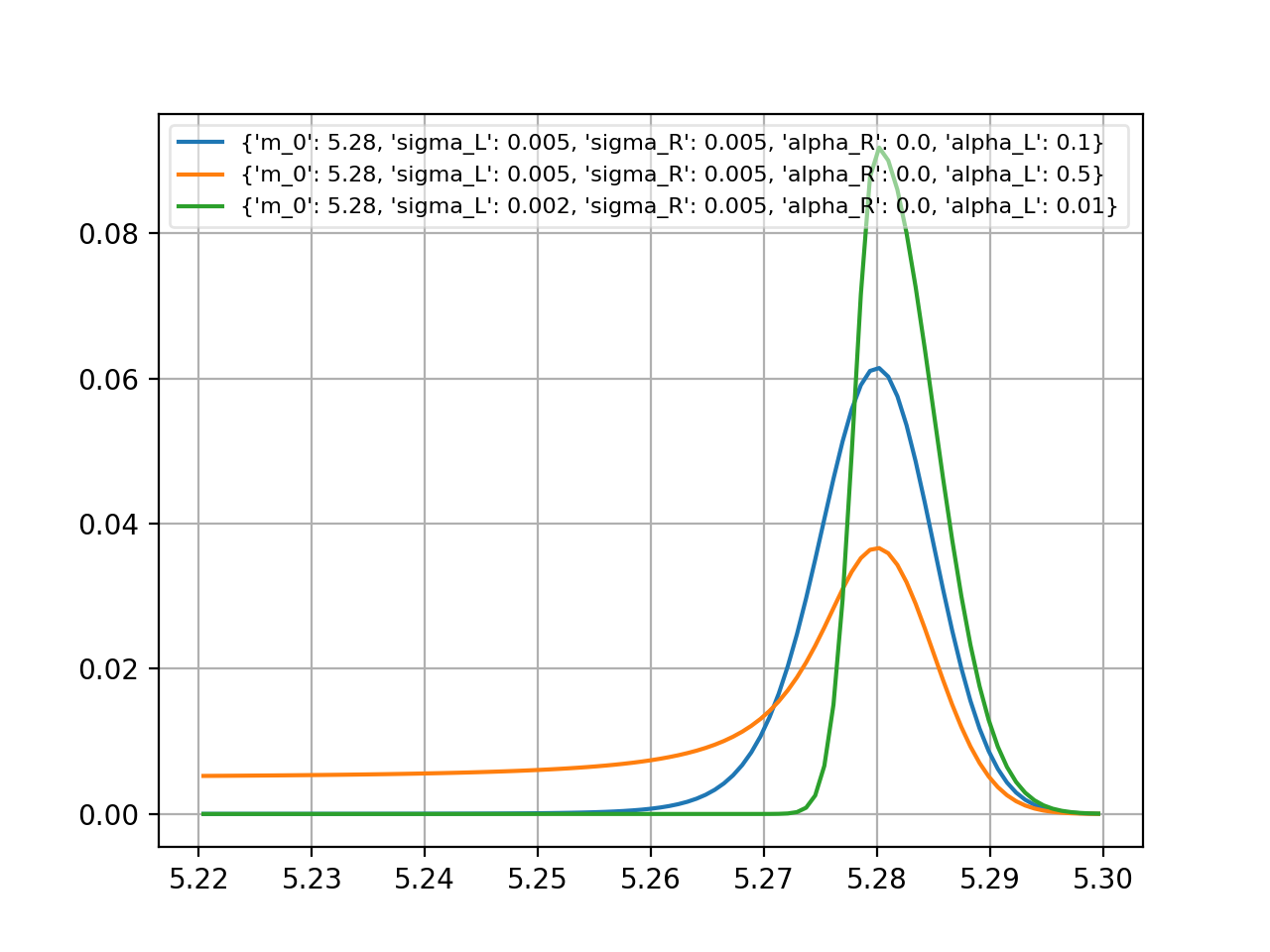
cruijff¶
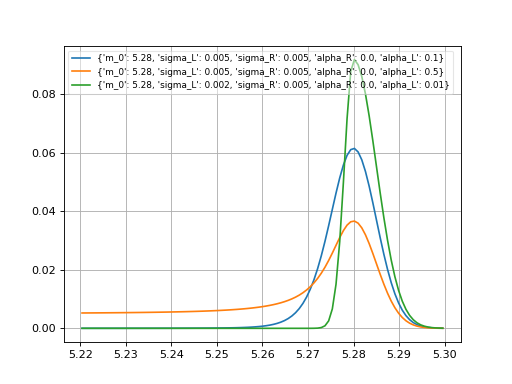
- probfit.pdf.cruijff(double x, double m_0, double sigma_L, double sigma_R, double alpha_L, double alpha_R) → double¶
Unnormalized cruijff function
\[\begin{split}f(x;m_0, \sigma_L, \sigma_R, \alpha_L, \alpha_R) = \begin{cases} \exp\left(-\frac{(x-m_0)^2}{2(\sigma_{L}^2+\alpha_{L}(x-m_0)^2)}\right) & \mbox{if } x<m_0 \\ \exp\left(-\frac{(x-m_0)^2}{2(\sigma_{R}^2+\alpha_{R}(x-m_0)^2)}\right) & \mbox{if } x<m_0 \\ \end{cases}\end{split}\]
(Source code, png, hires.png, pdf)
doublegaussian¶
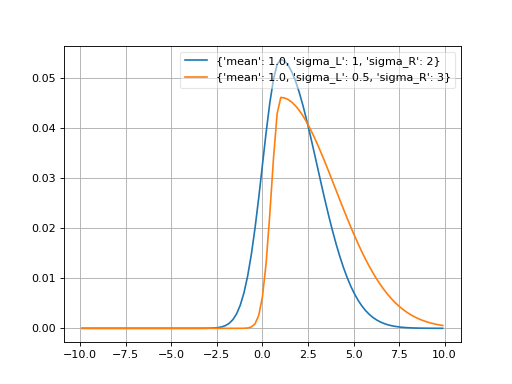
- probfit.pdf.doublegaussian(double x, double mean, double sigma_L, double sigma_R) → double¶
Unnormalized double gaussian
\[\begin{split}f(x;mean,\sigma_L,\sigma_R) = \begin{cases} \exp \left[ -\frac{1}{2} \left(\frac{x-mean}{\sigma_L}\right)^2 \right], & \mbox{if } x < mean \\ \exp \left[ -\frac{1}{2} \left(\frac{x-mean}{\sigma_R}\right)^2 \right], & \mbox{if } x >= mean \end{cases}\end{split}\]
(Source code, png, hires.png, pdf)
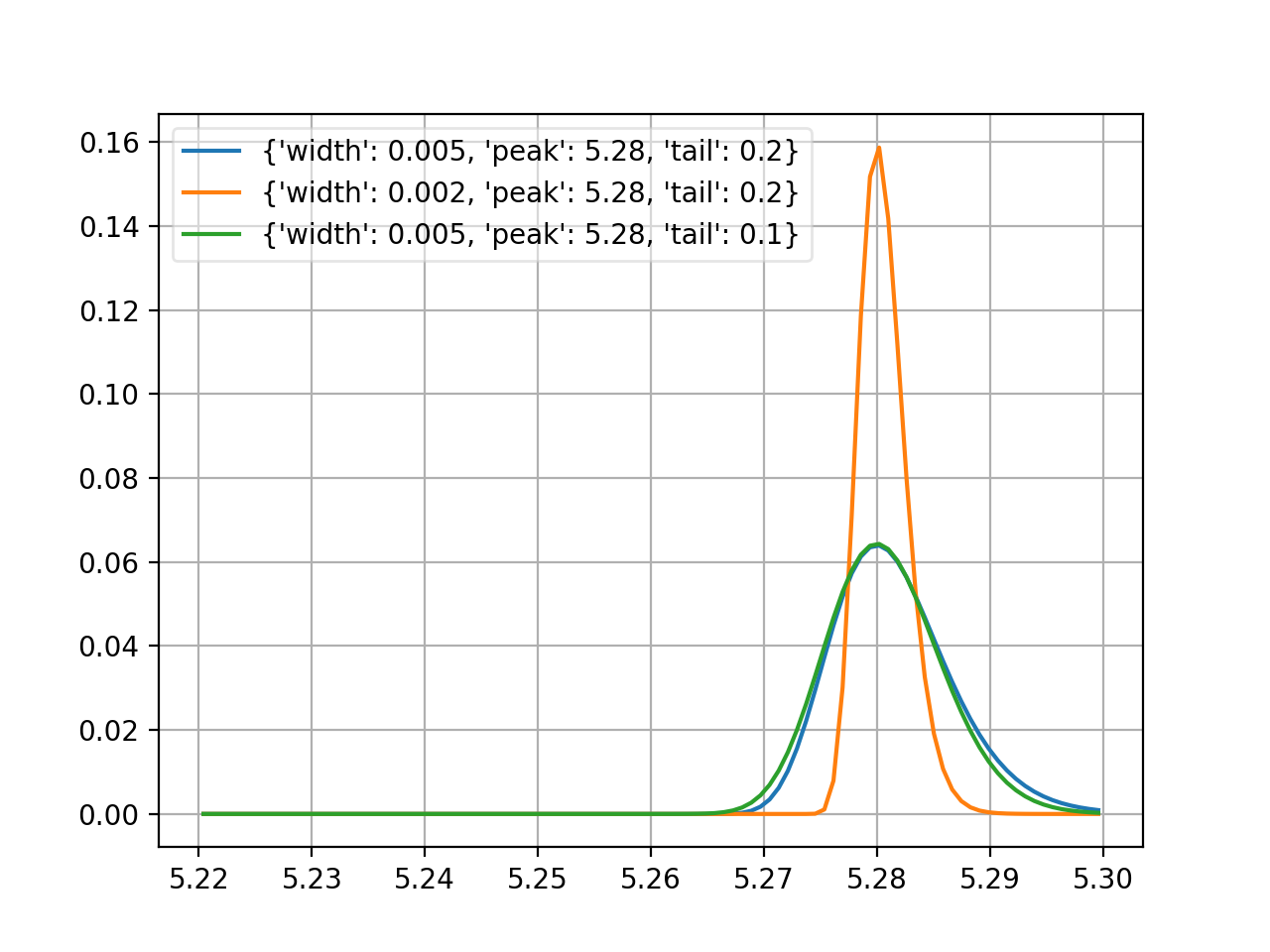
novosibirsk¶
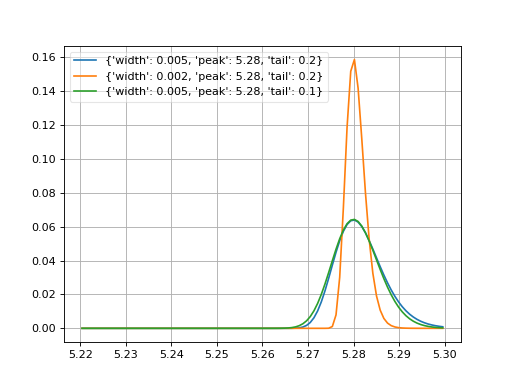
- probfit.pdf.novosibirsk(double x, double width, double peak, double tail) → double¶
Unnormalized Novosibirsk
\[\begin{split}f(x;\sigma, x_0, \Lambda) = \exp\left[ -\frac{1}{2} \frac{\left( \ln q_y \right)^2 }{\Lambda^2} + \Lambda^2 \right] \\ q_y(x;\sigma,x_0,\Lambda) = 1 + \frac{\Lambda(x-x_0)}{\sigma} \times \frac{\sinh \left( \Lambda \sqrt{\ln 4} \right)}{\Lambda \sqrt{\ln 4}}\end{split}\]where
width = \(\sigma\)
peak = \(m_0\)
tail = \(\Lambda\)
(Source code, png, hires.png, pdf)
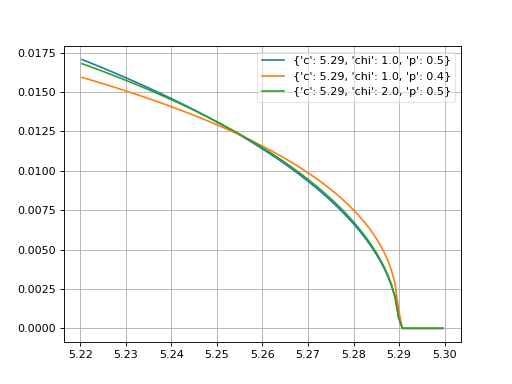
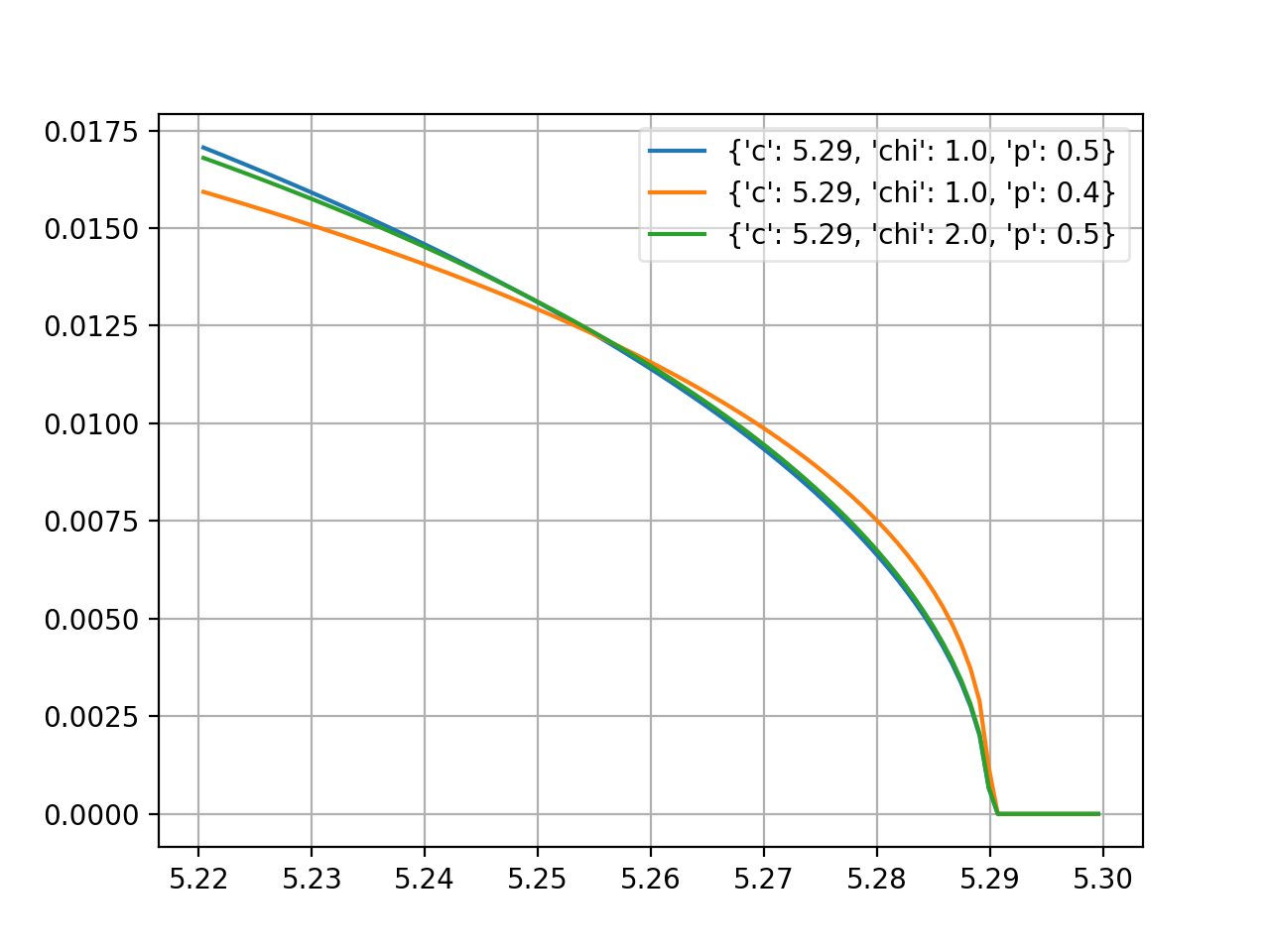
argus¶
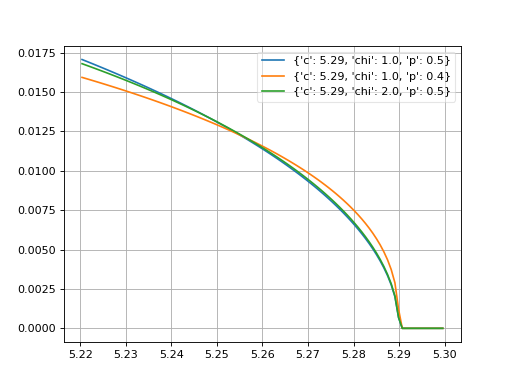
- probfit.pdf.argus(double x, double c, double chi, double p) → double¶
Unnormalized argus distribution
\[f(x;c,\chi,p) = \frac{x}{c^2} \left( 1-\frac{x^2}{c^2} \right) \exp \left( - \frac{1}{2} \chi^2 \left( 1 - \frac{x^2}{c^2} \right) \right)\]
(Source code, png, hires.png, pdf)
poly2¶
- probfit.pdf.poly2(double x, double a, double b, double c) → double¶
Parabola
\[f(x;a,b,c) = ax^2+bx+c\]
poly3¶
- probfit.pdf.poly3(double x, double a, double b, double c, double d) → double¶
Polynomial of third order
\[f(x; a,b,c,d) =ax^3+bx^2+cx+d\]
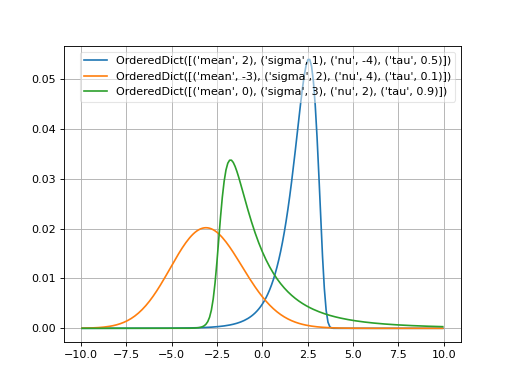
JohnsonSU¶
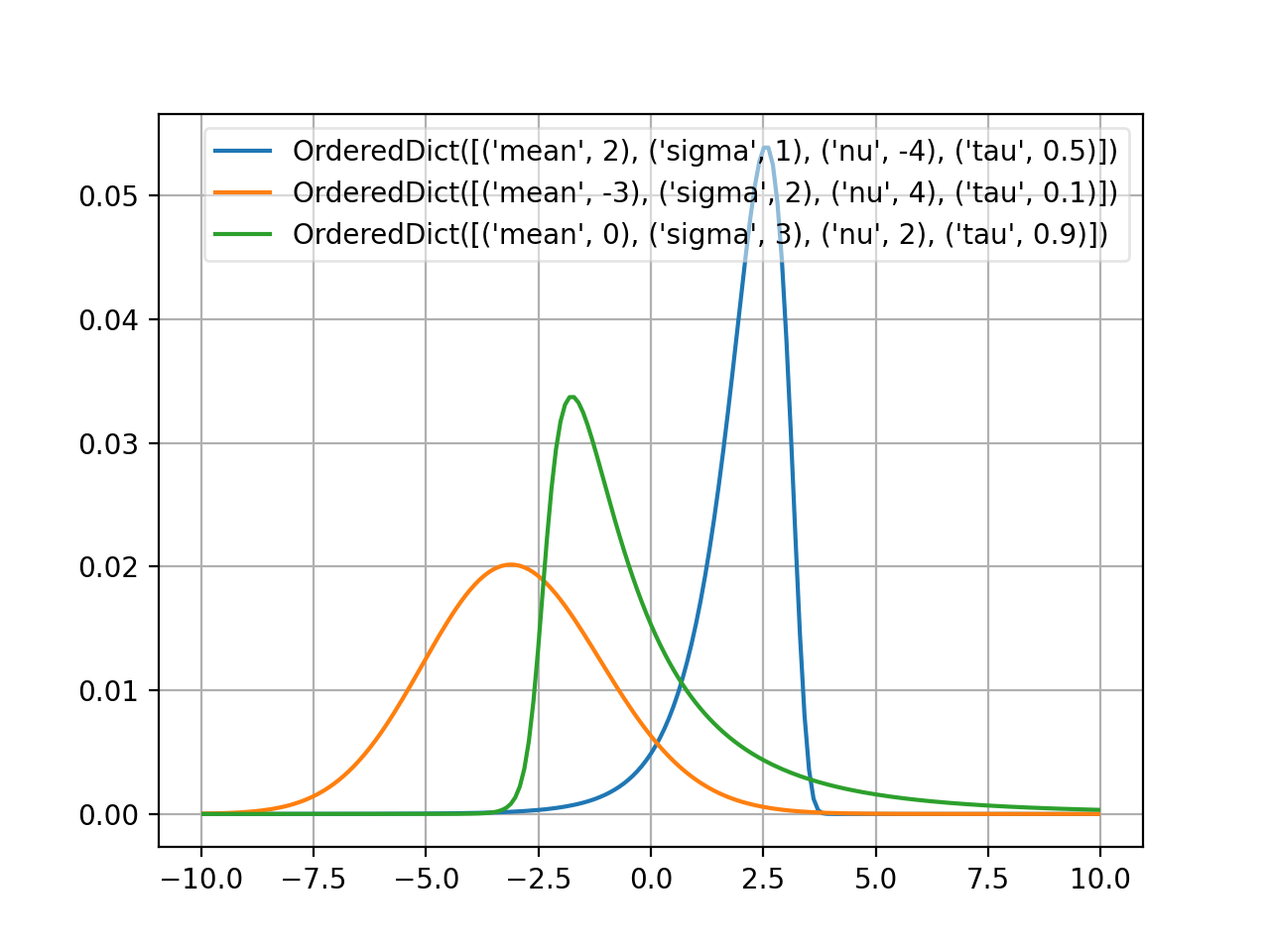
- probfit.pdf.johnsonSU()¶
_JohnsonSU(xname=’x’)
Normalized JohnsonSU [1]_.
\[f(x; \mu, \sigma, \nu, \tau) = \frac{1}{\lambda \sqrt{2\pi}} \frac{1}{\sqrt{1 + \left( \frac{x - \xi}{\lambda} \right)}} e^{-\frac{1}{2} \left( -\nu + \frac{1}{\tau} \sinh^{-1} \left( \frac{x - \xi}{\lambda} \right)\right)^{2}}\]where
\[\begin{split}\lambda = \sigma \times \left(\frac{1}{2}( \exp(\tau^{2}) - 1) \left(\exp(\tau^{2}) \cosh\left(-\nu \tau \right) + 1\right) \right)^{-\frac{1}{2}} \\\end{split}\]and
\[\xi = \mu + \lambda \exp\left(\frac{\tau^{2}}{2}\right)\sinh \left( \nu \tau \right)\]
(Source code, png, hires.png, pdf)
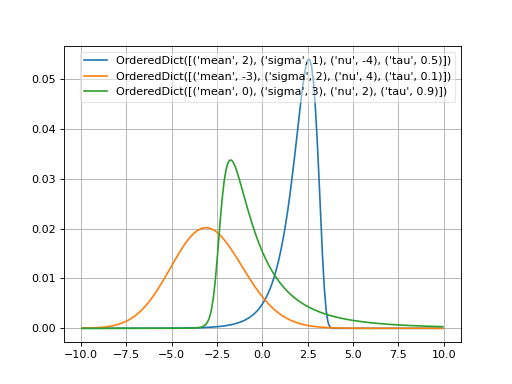
Exponential¶
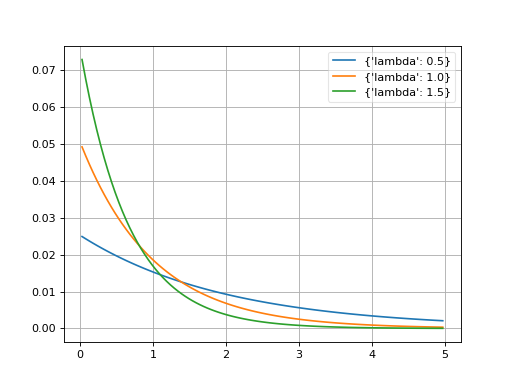
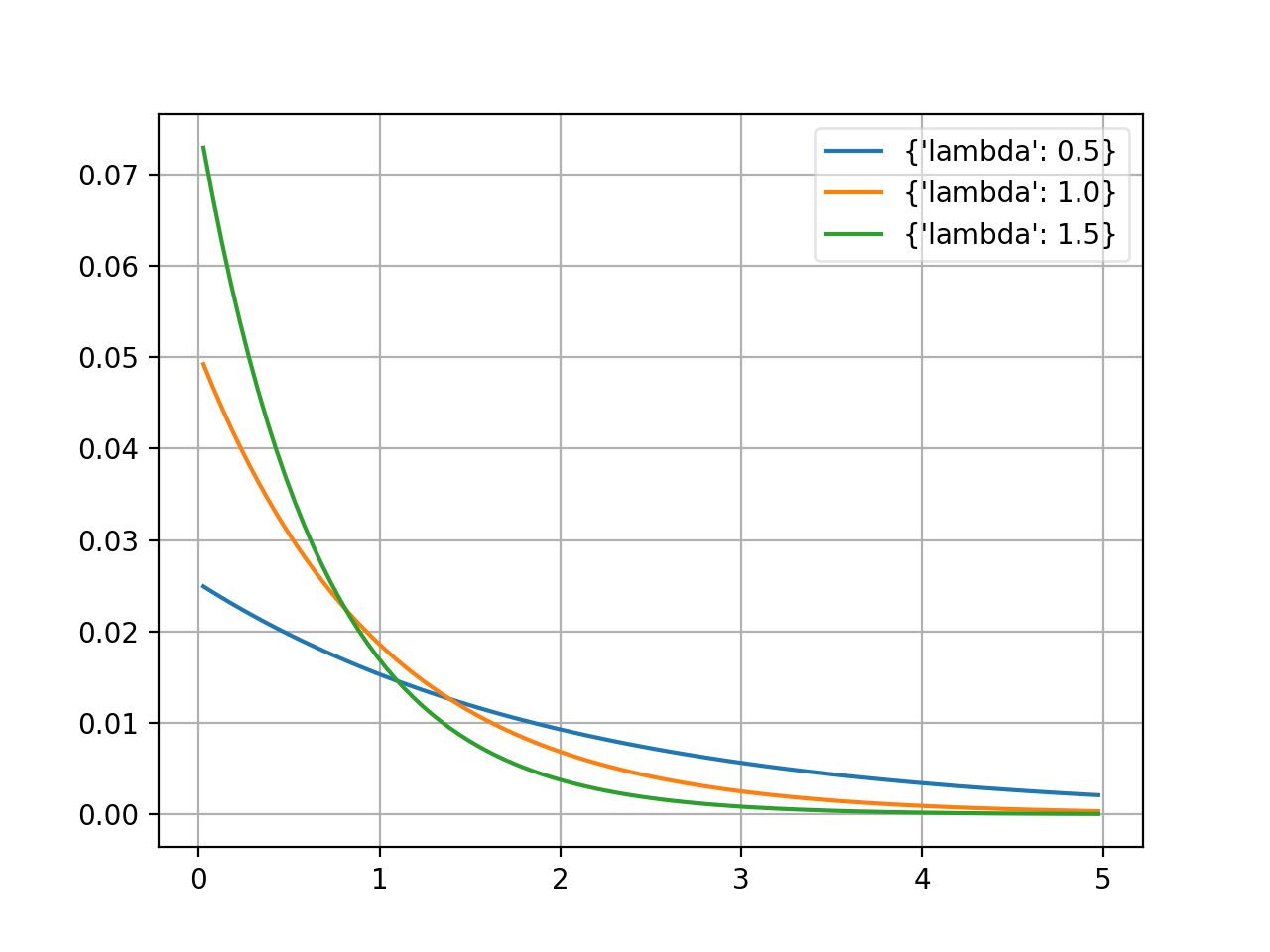
- probfit.pdf.exponential()¶
_Exponential(xname=’x’)
Exponential [1]_.
\[\begin{split}f(x;\tau) = \begin{cases} \exp \left(-\lambda x \right) & \mbox{if } \x \geq 0 \\ 0 & \mbox{if } \x < 0 \end{cases}\end{split}\]
(Source code, png, hires.png, pdf)
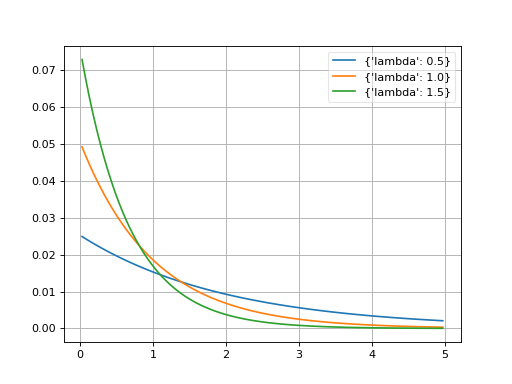
Polynomial¶
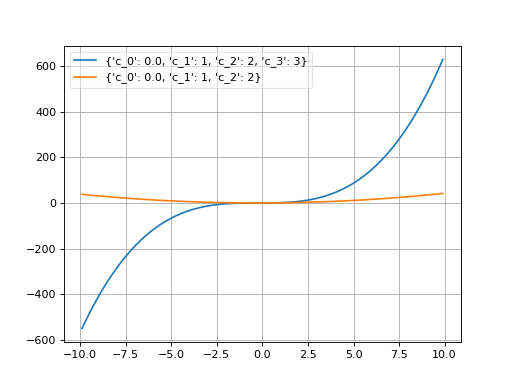
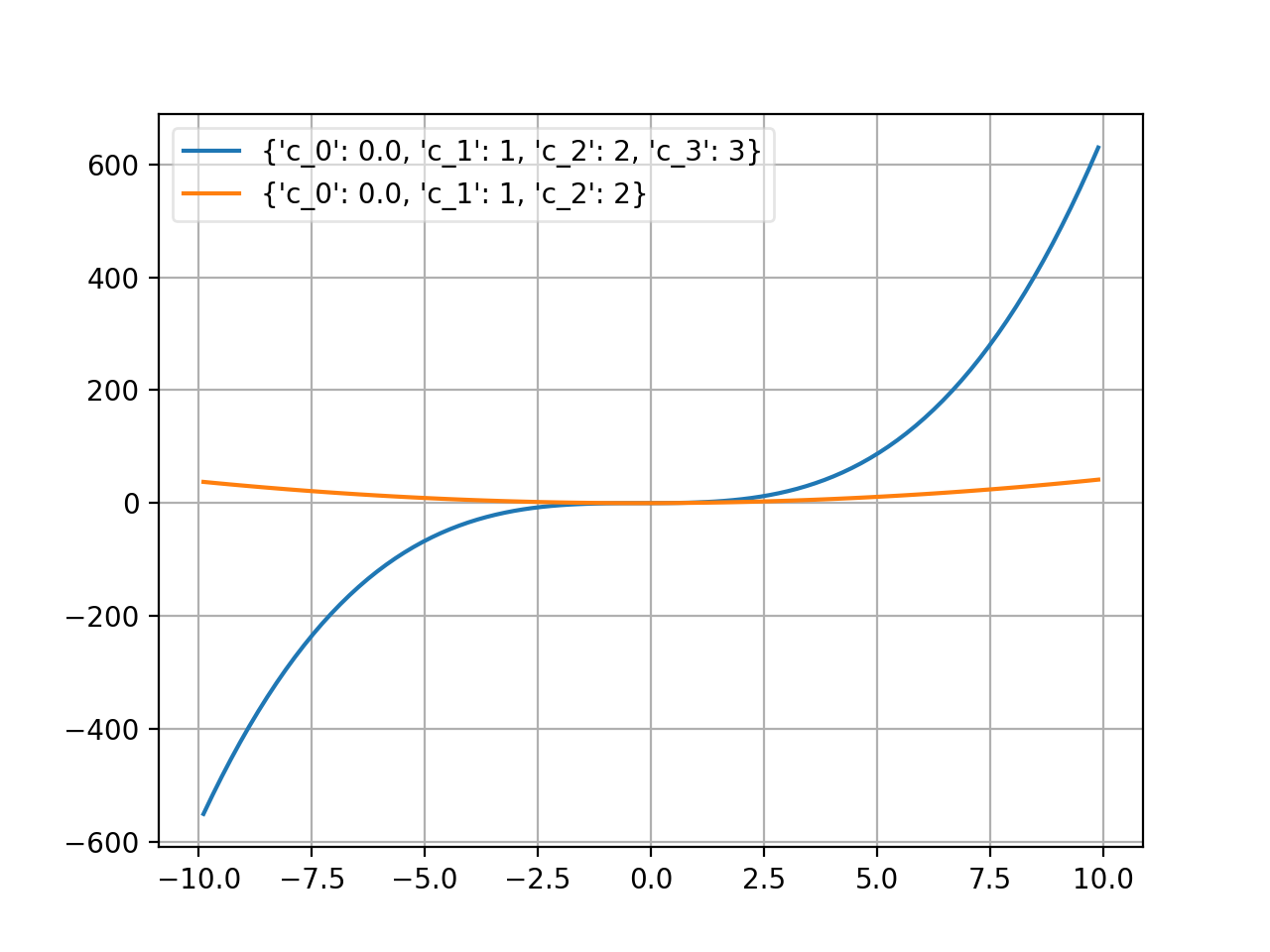
- class probfit.pdf.Polynomial(order, xname='x')¶
Polynomial.
\[f(x; c_i) = \sum_{i < \text{order}} c_i x^i\]User can supply order as integer in which case it uses (c_0….c_n+1) default or the list of coefficient name which the first one will be the lowest order and the last one will be the highest order. (order=1 is a linear function)
(Source code, png, hires.png, pdf)
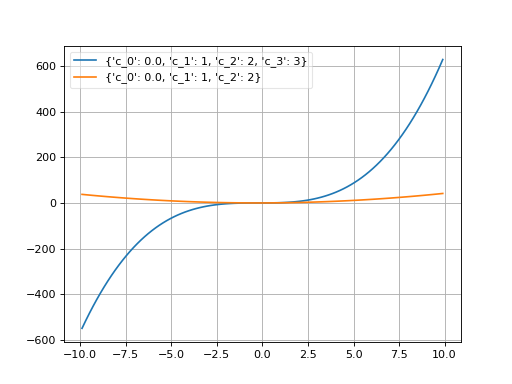
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Useful Utility Function¶
vector_apply¶
- probfit.nputil.vector_apply(f, x, *arg)¶
Apply f to array x with given arguments fast.
This is a fast version of:
np.array([f(xi,*arg) for xi in x ])
useful when you try to plot something.
draw_pdf¶
- probfit.plotting.draw_pdf(f, arg, bound, bins=100, scale=1.0, density=True, normed_pdf=False, ax=None, **kwds)¶
draw pdf with given argument and bounds.
Arguments
f your pdf. The first argument is assumed to be independent variable
arg argument can be tuple or list
bound tuple(xmin,xmax)
bins number of bins to plot pdf. Default 100.
scale multiply pdf by given number. Default 1.0.
density plot density instead of expected count in each bin (pdf*bin width). Default True.
normed_pdf Normalize pdf in given bound. Default False
The rest of keyword argument will be pass to pyplot.plot
Returns
x, y of what’s being plot
draw_compare_hist¶
- probfit.plotting.draw_compare_hist(f, arg, data, bins=100, bound=None, ax=None, weights=None, normed=False, use_w2=False, parts=False, grid=True)¶
draw histogram of data with poisson error bar and f(x,*arg).
data = np.random.rand(10000) f = gaussian draw_compare_hist(f, {'mean':0,'sigma':1}, data, normed=True)
Arguments
f
arg argument pass to f. Can be dictionary or list.
data data array
bins number of bins. Default 100.
bound optional boundary of plot in tuple form. If None is given, the bound is determined from min and max of the data. Default None
weights weights array. Default None.
normed optional normalized data flag. Default False.
use_w2 scaled error down to the original statistics instead of weighted statistics.
parts draw parts of pdf. (Works with AddPdf and Add2PdfNorm). Default False.
draw_residual¶
- probfit.plotting.draw_residual(x, y, yerr, xerr, show_errbars=True, ax=None, zero_line=True, grid=True, **kwargs)¶
Draw a residual plot on the axis.
By default, if show_errbars if True, residuals are drawn as blue points with errorbars with no endcaps. If show_errbars is False, residuals are drawn as a bar graph with black bars.
Arguments
x array of numbers, x-coordinates
y array of numbers, y-coordinates
yerr array of numbers, the uncertainty on the y-values
xerr array of numbers, the uncertainty on the x-values
show_errbars If True, draw the data as a bar plot, else as an errorbar plot
ax Optional matplotlib axis instance on which to draw the plot
zero_line If True, draw a red line at \(y = 0\) along the full extent in \(x\)
grid If True, draw gridlines
kwargs passed to
ax.errorbar(ifshow_errbarsis True) orax.bar(ifshow_errbarsif False)
Returns
The matplotlib axis instance the plot was drawn on.